บันทึกวิธีสรุปข้อมูลเพื่อนำไปสร้างกราฟ Ghaph/Chart 101 สำหรับนักวิทยาศาสตร์ข้อมูล Data Science - sprint 04
Data Transformation 101
data transformation เปรียบเสมือนการเล่นแร่แปรธาตุ ปรับเปลี่ยน data frame ให้อยู่ใน format อย่างที่เราต้องการ โดยในภาษา R ที่เรียนกันไปใน sprint ที่ 3 จะใช้ dplyr ในกลุ่มฟังก์ชัน tidyverse
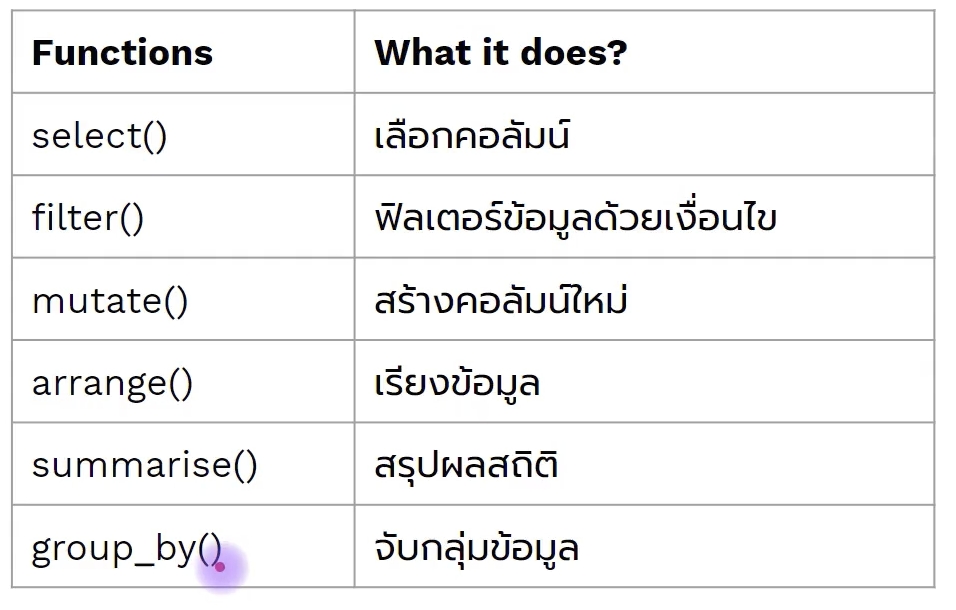
5 ฟังก์ชันใน dplyr ได้แก่
- select()
- filter()
- mutate()
- arrange()
- summerise() หรือ summerize ก็ได้
จงใช้เครื่องมืออย่างฉลาด - “Wong (Dr. Strange, 2016)”
workflow สำหรับ data analyst ที่เขียนด้วย R
- ดึงข้อมูลจาก SQL database หรือ data format ต่างๆ เข้าสู่ R Studio
- เขียน dplyr เพื่อจัดการ data frame ด้วยการ merge, join, union, transform
- ส่ง transformed data ให้ user ของเรา อาจจะเป็น csv, excel, json หรือส่งไปในรูปแบบ software ต่างๆ เช่น Power BI, Tableau, Google sheets, Data Studio
EP01 - Intro to Data Transformation
Data Transformation คืออะไร
การเปลี่ยนข้อมูลต้นฉบับ ให้เป็นหน้าตาตามที่เราต้องการ เปลี่ยน format เดิมให้อยู่ในรูปแบบที่เราสามารถวิเคราะห์ข้อมูลต่อได้
เราจะใช้ R ในการเรียนรู้ในเรื่องนี้ โดยที่จะต้องติดตั้ง library ที่จำเป็น
ความหมายของในแต่ละฟังก์ชัน
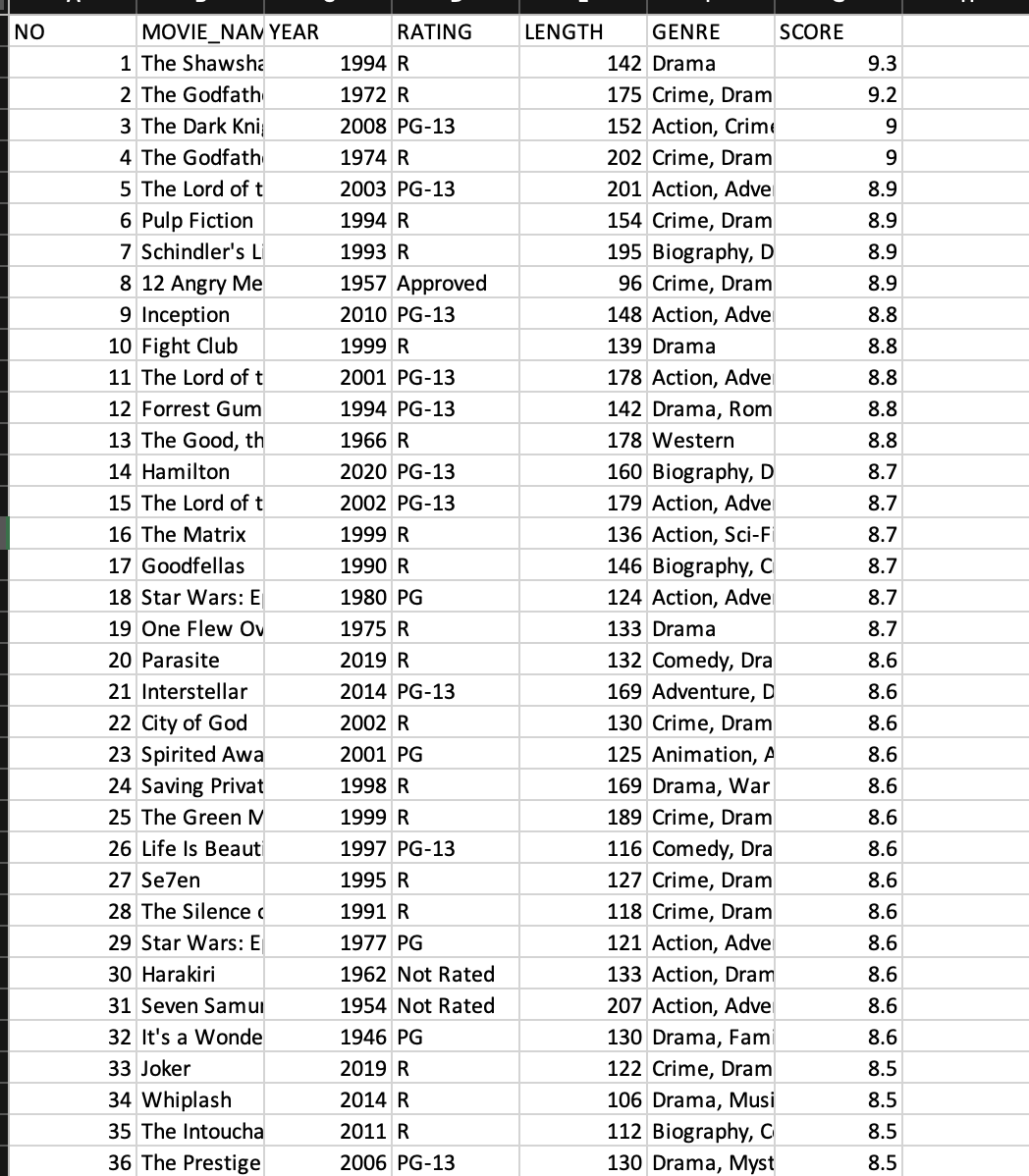
คราวนี้เราก็โหลดข้อมูลชุดนี้ไปอยู่ใน RStudio ตามที่ได้เรียนใน. Sprint 03 R Programming
ติดตั้ง library และ โหลด ที่เขียนเอาไว้ในตอนต้น

จากนั้นก็ เรียกข้อมูลมาเก็บเอาไว้ในตัวแปร แล้วสร้างเป็นไฟล์ Dataframe เอาไว้
imdb <- read.csv('imdb.csv')
View(imdb)
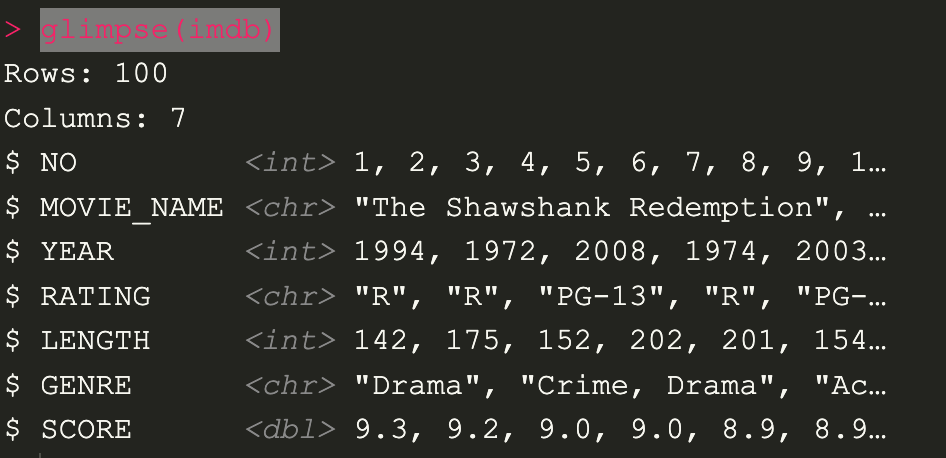
คำสั่งนี้เป็นคำสั่งสำหรับ review data structure
glimpse(imdb)
เราจะเห็นว่ามี column อยู่ 7 และแสดง type ข้อมูลต่างๆ
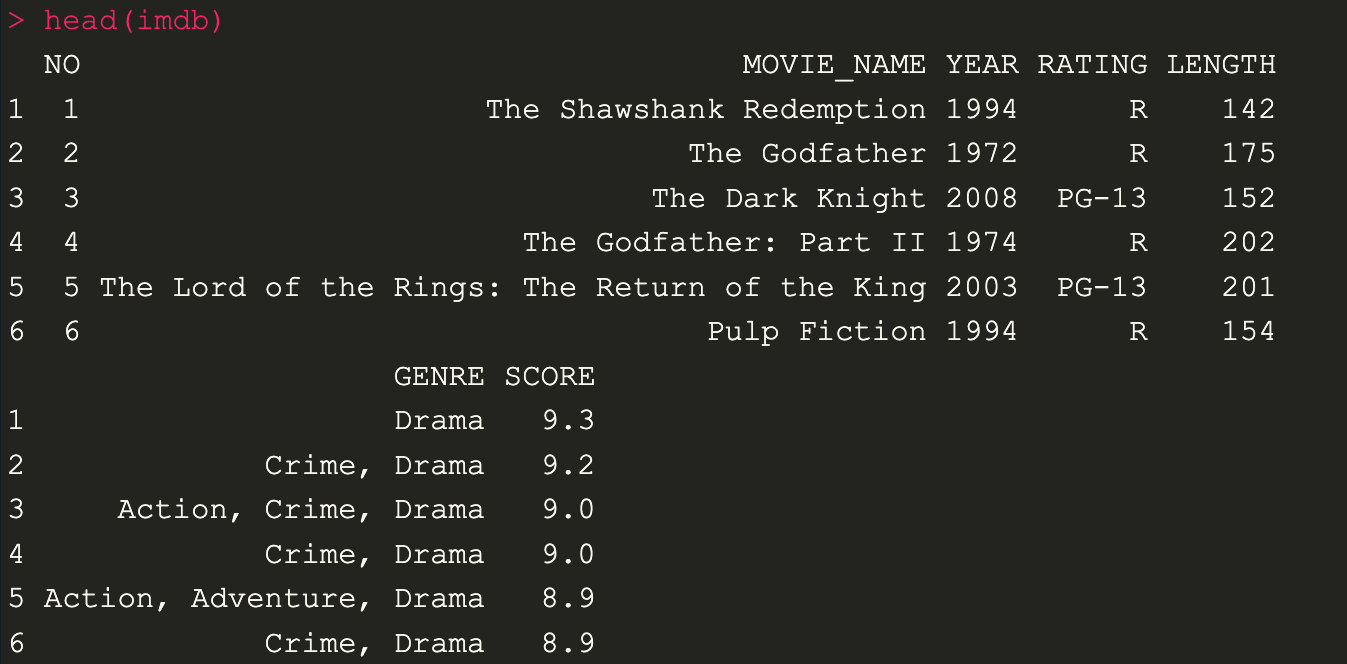
คำสั่งนี้เป็นการ print แสดงข้อมูลส่วน หัว และส่วนท้ายของชุดข้อมูล ก็คือ head และ tail จำนวน 6 แถวเป็น default เราสามารถที่จะแสดงจำนวนแถวตามที่เราต้องการได้เช่นเดียวกัน
head(imdb) // display 6 row
head(imdb, 10) // display 10 row
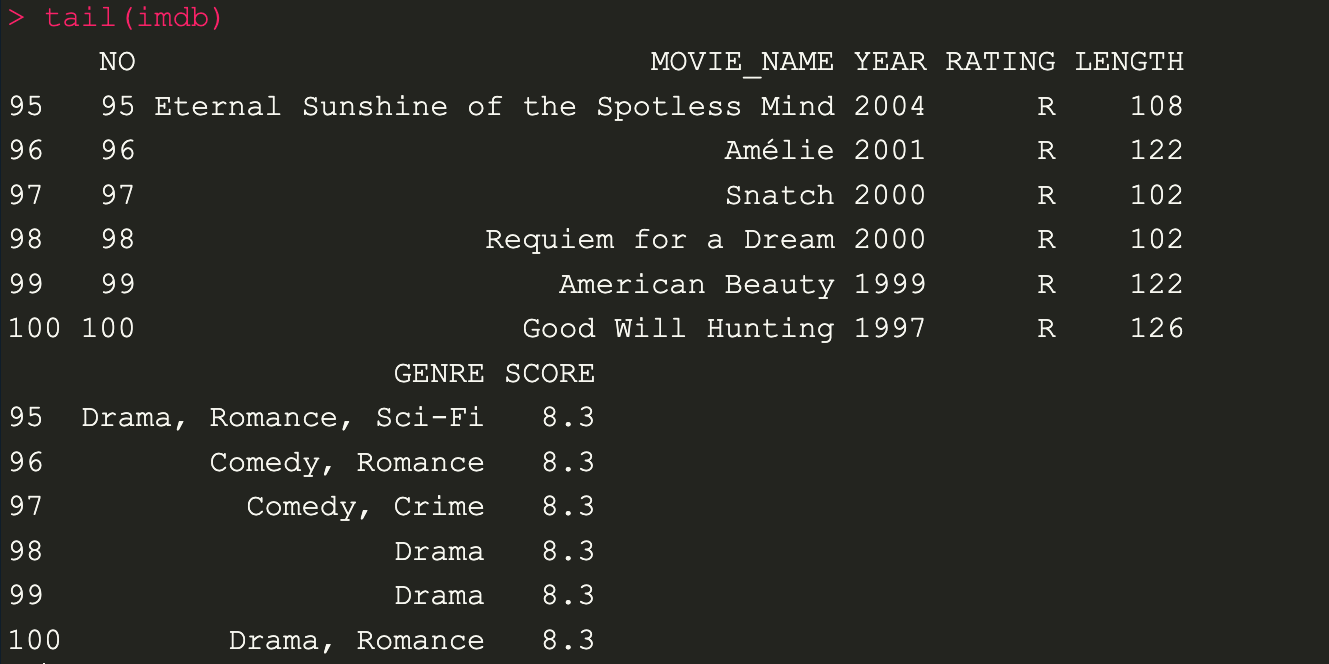
tail(imdb) // display 6 row
tail(imdb,10) // display 10 row

EP03 - Select Columns
ฟังก์ชันที่จะได้ใช้ ในบทนี้ จะมี Pipe Operator ด้วย
dplyr มี pipe operator %>% ที่ใช้ในการเขียน pipeline เช่น
# load dplyr
library(dplyr)
# select columns
select(mtcars, mpg, wt, hp)
mtcars %>% select(mpg, wt, hp)
ข้อดีของ pipeline คือ เราสามารถเชื่อมฟังก์ชันของเราได้หลาย steps เช่น
df %>% select() %>% filter() %>% mutate() %>% arrange()
คราวนี้มาดูฟังก์ชัน Select ฟังก์ชันของบทนี้กันบ้าง โดยใช้ Data set imdb
ฟังก์ชัน select เป็นฟังก์ชันสำหรับเลือกข้อมูล column มาแสดง โดยจะเลือกตามชื่อ column
เราจะรู้ชื่อ column ได้อย่างไร
สามารถเปิดดู attribute โดยใช้คำสั่ง names แล้วใส่ object เข้าไป names(imdb)
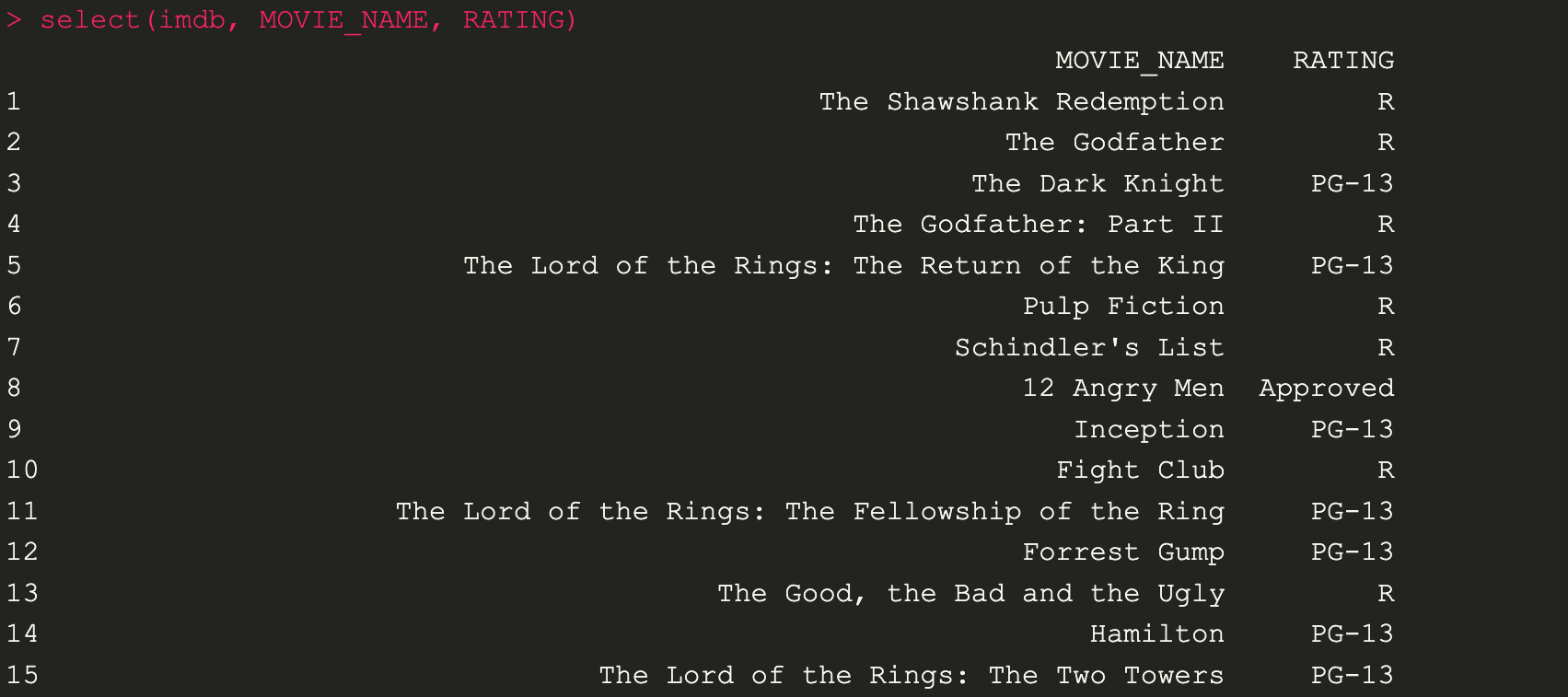
เลือกชื่อ column ที่อยากเอามาแสดง
select(imdb, MOVIE_NAME, RATING)
select(imdb, 1, 5) // ใช้เลข column ก็ได้
แสดงออกมา 100 แถว
เราสามารถเปลี่ยนชื่อ column ได้ด้วย
select(imdb, movie_name = MOVIE_NAME)
// movie_name คือ ชื่อคอลัมน์ใหม่
// MOVIE_NAME คือ ชื่อคอลัมน์เก่า
คราวนี้เรามาใช้ pipe operator กัน
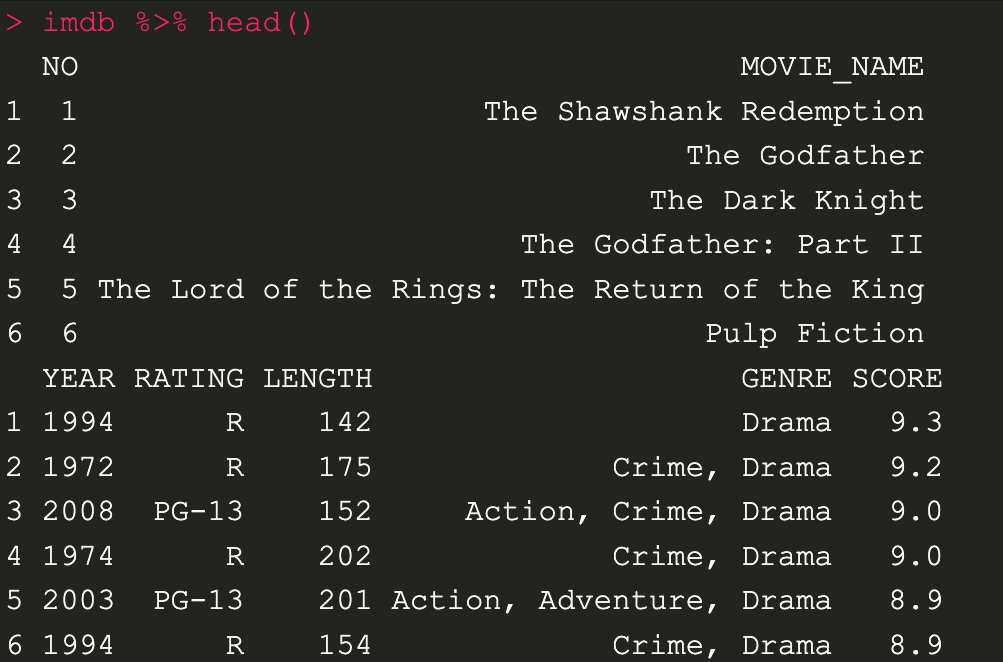
มาลองดู คำสั่งชุดนี้กันก่อน สิ่งที่ pipe มาทำ ในขั้นตอนแรก มันจะดึง object ที่อยู่ใน imdp ผ่านเข้า operator %>% แล้วนำ object นี้ไปเข้า head() สังเกตได้ว่าจะมีข้อมูลที่แสดงออกมาเหมือนกับพิมพ์แค่ head() เฉยๆ
imdb %>% head()

แต่เราจะเอามาใช้กับ select()
imdb %>% select(movie_name = MOVIE_NAME) // select ไม่ได้ใส่ object เหมือนคำสั่งที่ผ่านมา
อีกตัวอย่างเช่น
imdb %>% select(movie_name = MOVIE_NAME) %>% head()

EP04 - Filter Data - 1
function filter ใช้สำหรับกรองข้อมูลที่ต้องการใน data frame
data set ที่ผ่านมาคือ imdb
ลอง ใส่เงื่อนไข SCORE มากกว่าหรือเท่ากับ 9.0 ดู
filter(imdb, SCORE >= 9.0)
หากเราไม่รู้ว่า Columns มีชื่อว่าอะไรบ้าง ใช้ names() เพื่อดูข้อมูล
names(imdb)
// [1] "NO" "MOVIE_NAME" "YEAR"
// [4] "RATING" "LENGTH" "GENRE"
// [7] "SCORE"
เพื่อให้ง่ายต่อการพิมพ์ ชื่อคอลัมน์ต่างๆที่เป็นตัวพิมพ์ใหญ่ ให้ lower ตัวอักษรจะได้พิมพ์ได้ง่ายขึ้น
names(imdb) <- tolower(names(imdb))
จากนั้น มาลองเครื่องหมาย pipe เพื่อเชื่อมข้อมูลจากหลายๆฟังก์ชันกันบ้าง โดยเราจะดึงข้อมูลจาก dataframe ไปเข้าฟังก์ชัน select เพื่อเลือก movie_name , year และ score ออกมาแล้ว filter score
imdb %>% select(movie_name, year, score) %>% filter(score >= 9)
/*
movie_name year score
1 The Shawshank Redemption 1994 9.3
2 The Godfather 1972 9.2
3 The Dark Knight 2008 9.0
4 The Godfather: Part II 1974 9.0
*/
ฟังกชัน filter ที่ได้ค่ามาจาก pipe ยังสามารถใส่เงื่อนไข ได้มากกว่า 1 เงื่อนไขโดยใช้ operator & (and) และ | (or) เช่น
imdb %>% select(movie_name, year, score) %>% filter(score >= 9 & year > 2000)
/*
movie_name year score
1 The Dark Knight 2008 9
*/
imdb %>% select(movie_name, year, score) %>% filter(score == 8.8 | score == 8.3)
/*
movie_name year score
1 Inception 2010 8.8
2 Fight Club 1999 8.8
3 The Lord of the Rings: The Fellowship of the Ring 2001 8.8
4 Forrest Gump 1994 8.8
5 The Good, the Bad and the Ugly 1966 8.8
*/
การใช้ or มันจะค่อนข้างยาว มี shortcut ที่ช่วยให้สั้นขึ้น โดยใส่ค่าเอาไว้ใน vector
imdb %>% select(movie_name, year, score) %>% filter(score %in% c(8.8, 8.3, 8.9))
EP05 - Filter Data - 2
filter string columns
เราสามารถที่จะ filter ข้อมูลที่เป็น String ได้เช่นกัน โดยลองดึงค่าจาก genre (ประเภทหนัง) เป็นประเภท Drama
imdb %>% select(movie_name, genre, rating) %>% filter(genre == "Drama")
/*
movie_name genre rating
1 The Shawshank Redemption Drama R
2 Fight Club Drama R
3 One Flew Over the Cuckoo's Nest Drama R
4 American History X Drama R
5 Cinema Paradiso Drama R
*/
จากผลลัพท์ใน genre จริงๆแล้ว จะมีมากกว่า 1 ประเภท ที่ถูกแบ่งวรรคด้วย comma เช่น Drama, Comedy, Romance ซึ่งจะไม่ถูกดึงออกมาด้วย คราวนี้จะมาใช้ฟังก์ชัน grepl() เพื่อดึงค่าที่ต้องการออกมาจากถูกแถวที่มีค่า
grepl("Drama", imdb$genre)
/*
[1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[9] FALSE TRUE TRUE TRUE FALSE TRUE TRUE FALSE
[17] TRUE FALSE TRUE TRUE TRUE TRUE FALSE TRUE
[25] TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE
[33] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[41] FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE
[49] FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE
[57] TRUE FALSE TRUE FALSE FALSE TRUE FALSE TRUE
[65] TRUE FALSE TRUE TRUE FALSE FALSE TRUE FALSE
[73] TRUE TRUE FALSE TRUE FALSE TRUE TRUE FALSE
[81] TRUE TRUE TRUE TRUE TRUE FALSE TRUE TRUE
[89] TRUE TRUE TRUE TRUE FALSE TRUE TRUE FALSE
[97] FALSE TRUE TRUE TRUE
*/
ตรงไหนที่มีค่าที่เราต้องการหา มันจะเป็น TRUE เราสามารถที่จะนำค่านี้ไปใส่ใน filter ได้เลย
imdb %>% select(movie_name, genre, rating) %>% filter(grepl("Drama", imdb$genre))
ค่าใน grepl เป็น case sensitive พิมพ์เล็ก พิมพ์ใหญ่ เป็นคนละค่ากัน เวลา filter จะต้องระวัง
EP06 - Create Column
ในการสร้าง column ใหม่จะใช้ฟังก์ชัน ชื่อ mutate()
imdb %>% mutate(score_group = if_else(score >= 9, "High Rating", "Low Rating"))
???? if_else เป็น ฟังก์ชัน if else
สามารถที่จะสร้างมากกว่า 1 column ใหม่ได้
imdb %>% select(movie_name, score, length) %>% mutate(score_group = if_else(score >= 9, "High Raging", "Low Rating"),length_group = if_else(length >= 120, "Long Film", "Short Film"))
สังเกตว่าเราจะได้ column ใหม่ เพิ่มมาอีก 2 column
เราสามารถนำค่าที่ได้มาทำการ operation บวก ลบ คูณ หารได้ โดยใส่ operator เข้าไปที่ ข้อมูลที่เป็นตัวเลข ตัวอย่างเช่น
imdb %>%. select(movie_name, score) %>% mutate(score = score + 0.1) %>% head(10)
???? ชื่อ columne เวลาเราสร้างขึ้นมา แต่ยังคงเป็น code ที่ column เดิมเราสามารถแก้ชื่อ column ได้เลย
EP07 - Arrange Data
เราใช้ฟังก์ชัน arrange ในการ sort ค่าข้อมูล
imdb %>% arrange(length) %>% head(10)
ค่าที่ได้จะเรียงจาก น้อยไปมาก
ในกรณที่ต้องการจะเรียงจาก มากไปน้อย เราสามารถใช้ desc เข้าไปใน length เพื่อ sort ใหม่ได้
imdb %>% arrange(desc(length)) %>% head(10)
เราสามารถที่จะ sort แบบเรียงกันได้
imdb %>% arrange(rating, desc(length))
EP08 - Statistic Summery
เวลาที่จะสรุปค่าใน R เราใช้ summarise และ group_by ในการหาค่าสถิติ โดย แบ่งตามกลุ่ม
imdb %>% summarise(mean_length = mean(length))
เวลาที่ใช้ฟังก์ชัน summarise จะสร้าง columnขึ้นมาใหม่ 1 column
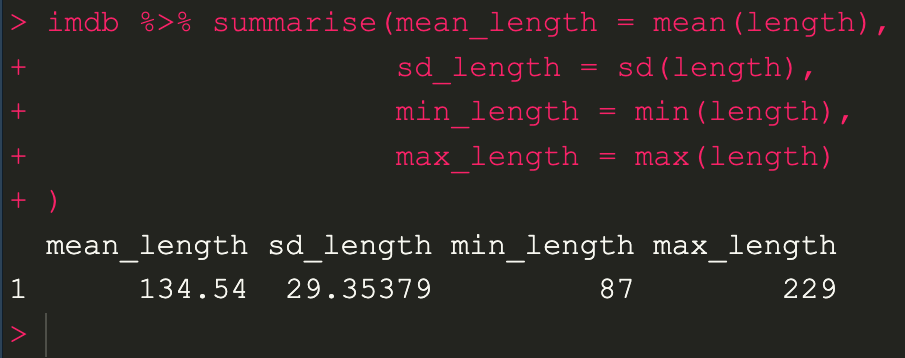
imdb %>% summarise(mean_length = mean(length), sd_length = sd(length), min_length = min(length), max_length = max(length)
)ถ้าอยากนับจำนวนข้อมูลทั้งหมดให้ใช้ ฟังก์ชัน n()
imdb %>% summarise(mean_length = mean(length), sd_length = sd(length), min_length = min(length), max_length = max(length), n = n()
)

คราวนี้เราจะมาเอาค่าสถิติที่คำนวนเอาไว้มาจัดกลุ่มตาม rating ของหนัง
imdb %>%
group_by(rating) %>%
summarise(mean_length = mean(length), sd_length = sd(length), min_length = min(length), max_length = max(length), n = n()
)
สังเกตว่า column ทางซ้ายสุดจะถูกจัดกลุ่มตาม กลุ่มที่มีใน rating ที่ใส่เข้าไปในฟังก์ชัน group_by
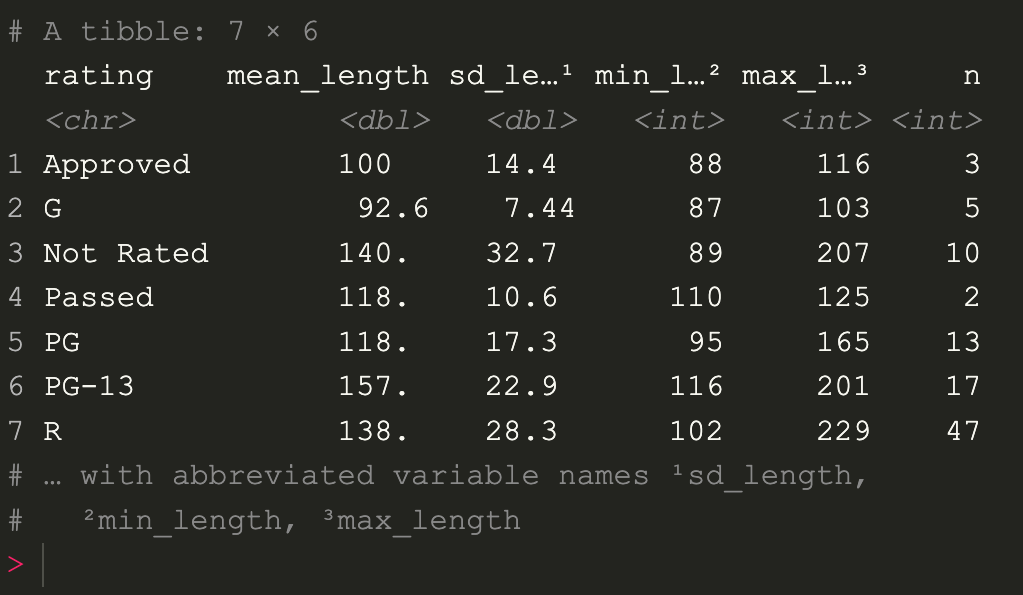
ให้ลองสังเกตที่ row ที่ 1 จะเป็นค่าว่าง ซึ่งมีหนังอยู่ 3 เรื่องที่ไม่มี rating เราจะตัดข้อมูลชุดนี้ออกโดยใส่เงื่อนไขลงไปในฟังก์ชัน filter
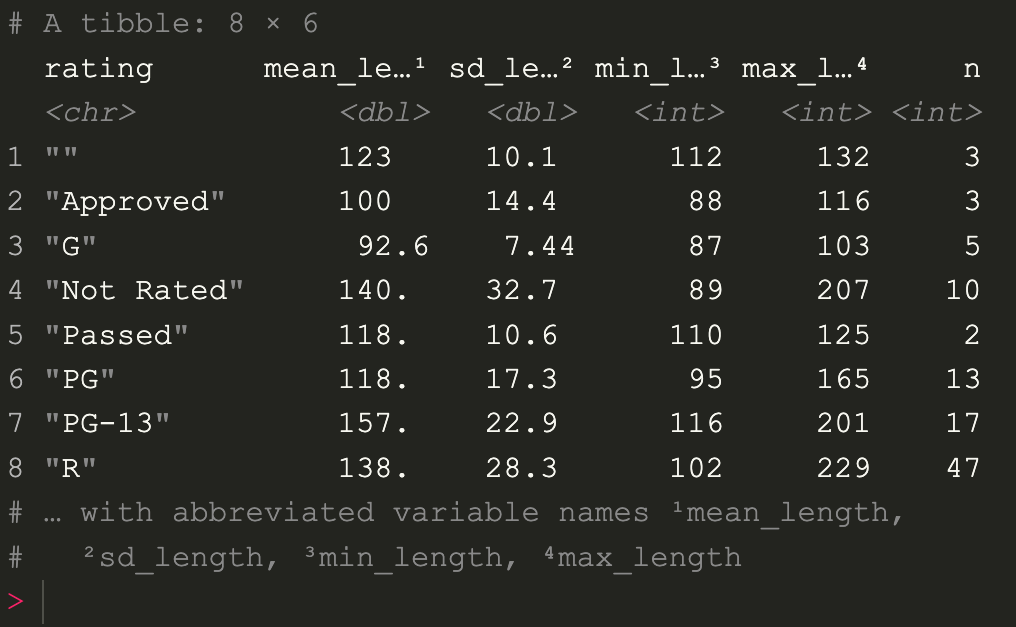
imdb %>%
filter(rating != "") %>%
group_by(rating) %>%
summarise(mean_length = mean(length), sd_length = sd(length), min_length = min(length), max_length = max(length), n = n()
)
EP09 - Join Tables
ตอนนี้เรามี data frame เพียงแค่ชุดเดียว ดังนั้นเราจะมาสร้าง data frame อีก 1 ชุดเพื่อจะมาเขียน join table กันได้
favorite_films <- data.frame(id = c(5,10,25,30,98))
data frame นี้จะมีแค่ 1 column
โจทย์คือเราอยากรู้ว่าหนังที่ได้จาก favorite_films มีชื่อหนังว่าอะไรบ้าง
favorite_films %>% inner_join(imdb, by = c("id" = "no") )
การ join นี้เป็นแบบ inner join และผลลัพท์ที่ได้ก็จะแสดงเฉพาะที่อยู่ใน favorite_films ก็คือ 5,10,25,30,98

EP10 - Export CSV File
หลังจากที่ได้วิเคราะห์ข้อมูลเสร็จเรียบร้อยเราสามารถที่จะ export file เพื่อไปวิเคราะห์ต่อได้ที่โปรแกรมอื่นๆ
# write csv file (export result)
imdb_prep <- imdb %>%
select(movie_name, released_year = year, rating, length, score) %>%
filter(rating == "R" & released_year > 2000)
# export file
write.csv(imdb_prep, "imdb_prep.csv", row.names = FALSE)
Data Transformation 102
ในบทนี้ จะเรียน function dplyr ที่ใช้จัดการ Dataframe รวมถึงการเขียน join
จุดประสงค์การเรียนรู้
- เข้าใจความแตกต่างของ tibble vs data.frame
- การสุ่มตัวอย่างด้วย sample_n()
- การ slice() ข้อมูลแถวที่ต้องการ
Tibble - EP01
tibble จะคล้ายกับ dataframe แต่ tibble จะยืดหยุ่นกว่า และการแสดงผลจะดีกว่าเพราะมันจะแสดงตาม ความกว้างของ console
df_tibble <- tibble(id =1:3, name = c("sklsongkiat", "jisoo", "lisa"))
Sample Data - EP02
sample เป็นการสุ่มตัวอย่างในข้อมูลที่ใส่เข้าไปในฟังก์ชัน
sample_n(mtcars, size=5)
ข้อมูลจะเปลี่ยนไปเรื่อยๆ แต่ถ้าเราไม่อยากให้เปลี่ยนเราจะต้องใช้คำสั่ง
set.seed(5)
sample_n(mtcars, size=5)
การสุ่มตัวอย่างแบบจำนวน percent ให้ใช้ sample_frac
sample ออกมา 20% และ replace เป็น true เพื่อบอกว่าผลลัพท์มีโอกาสซ้ำกัน
sample_frac(mtcars, size=0.2, replace=T)
Slice - EP03
ถ้าเราอยากจะ slice data จำนวนแถวออกมาดูเราสามารถเขียนแบบนี้ เพื่อดึงแถวที่เราต้องการออกมา
mtcars %>% slice(1:5)
mtcars[5:9, ]
slice(mtcars, 5:9)
คอร์สนี้ดีมากกกก (ไก่ ล้านตัว) ใครอ่านจบ แนะนำว่าให้ไปสมัครเรียน ติดตามได้ที่ link ด้านล่างนี้เลย
Course Online DATA ROCKIE Bootcamp