บันทึกวิธีสรุปข้อมูลเพื่อนำไปสร้างกราฟ Ghaph/Chart 103 สำหรับนักวิทยาศาสตร์ข้อมูล Data Science - sprint 04
Data visualization in R
R เกิดมาเพื่อทำ Visualization ด้วย Package ggplot
เนื้อหาในบทความนี้ ประกอบไปด้วย
- Why we need Data Viz?
- Exploratory Data Analysis
- Basic Plots (base R)
- Introduction to ggplot2
- Histogram
- Density
- Barplot
- Boxplot
- Scatter Plot
- Smooth
- Labels
- Theme + Facet + Color Scale
Why we need data viz
ทำไมต้องทำ visualization ด้วย
ทำไมต้องทำให้เป็นกราฟฟิก
เหตุผลเพราะ ตารางข้อมูลอย่าง Dataset ที่เห็นอยู่ด้านล่างนี้ จะเต็มไปด้วยตัวเลข ให้ลองถามตัวเองดูว่าดูรู้เรื่องไหม ดูไม่รู้เรื่องเลยต้องแปลงให้อยู่ในรูปแบบที่ทำความเข้าใจง่ายขึ้น
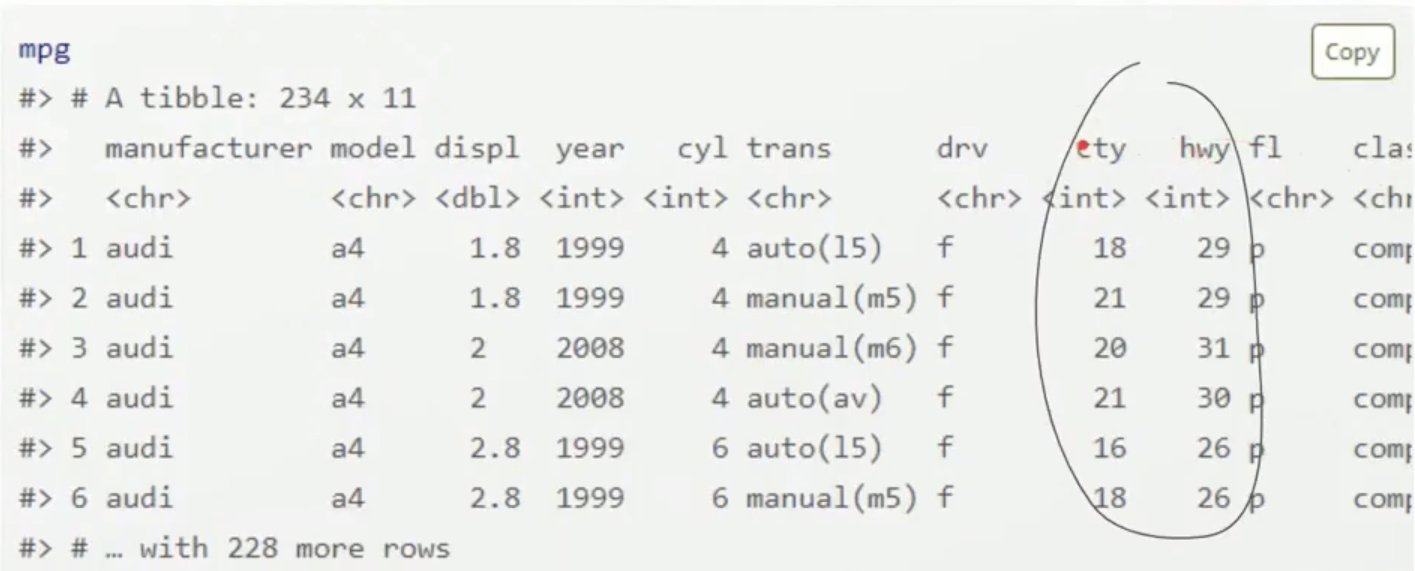
ยกตัวอย่าง ภาพด้านล่างนี้
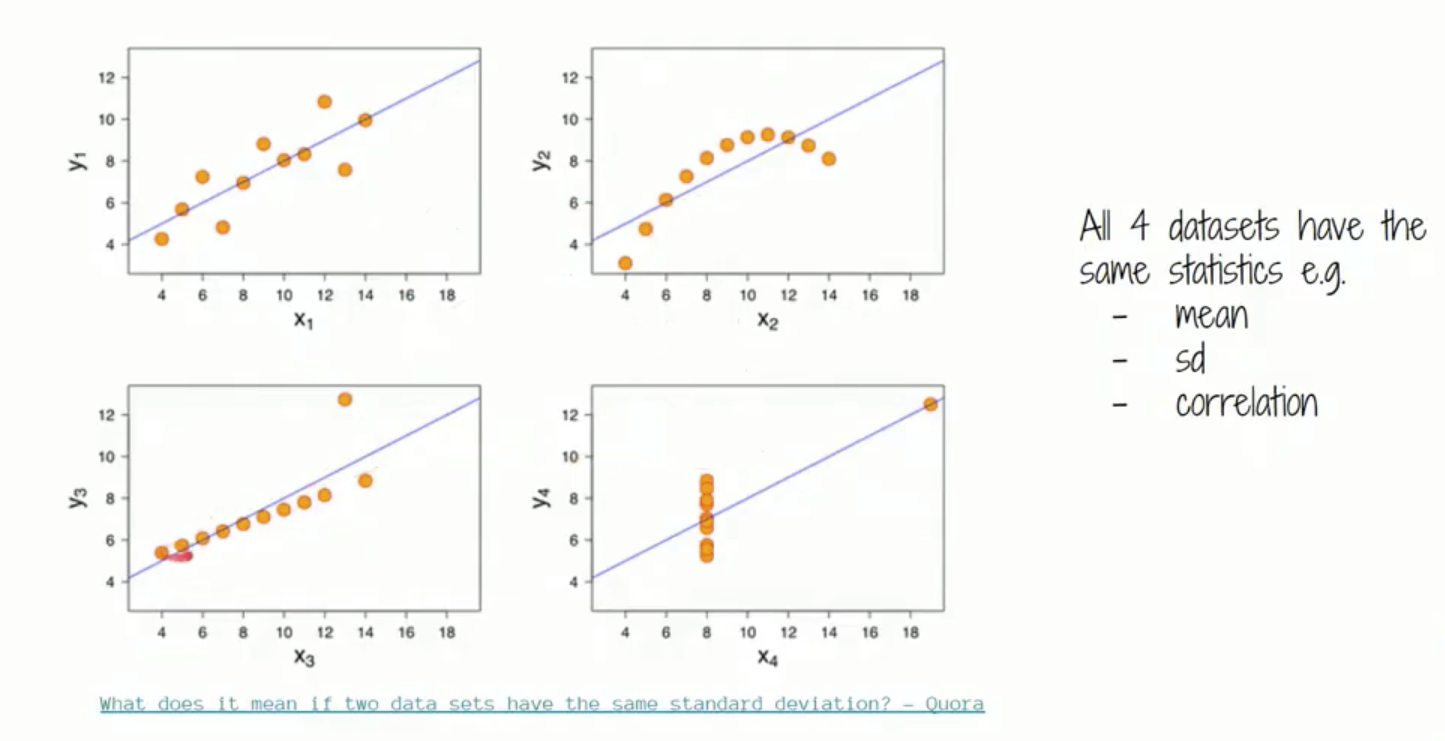
แม้ว่า Data set ที่ได้ออกหน้าตาของแสดง Scatter plot ไม่เหมือนกันเลย แต่ว่า
ค่าสถิติอาจจะเท่ากันหมดเลยก็ได้ อย่าง ค่า Mean, SD หรือ Correlation ซึ่งหมายความว่า ถ้าดูเป็นค่าตัวเลขในตาราง ไม่ได้หมายความว่า Dataset ทั้งหมดจะเหมือนกัน ซึ่งจำเป็นต้องมา Plot Graph เพื่อดู Plattern หรือหน้าตาจริงๆ
เจ้าพ่อสถิติแห่งการทำ Visualization

The Greatest value of a picture is when it forces us to notice what we never expected to see
แปลได้ว่า “การปรับเปลี่ยนช้อมูลให้เป็นรูปภาพ ทำเราเห็นคุณค่าบางอย่างที่อาจจะไม่ได้คาดคิดว่าจะเห็น”
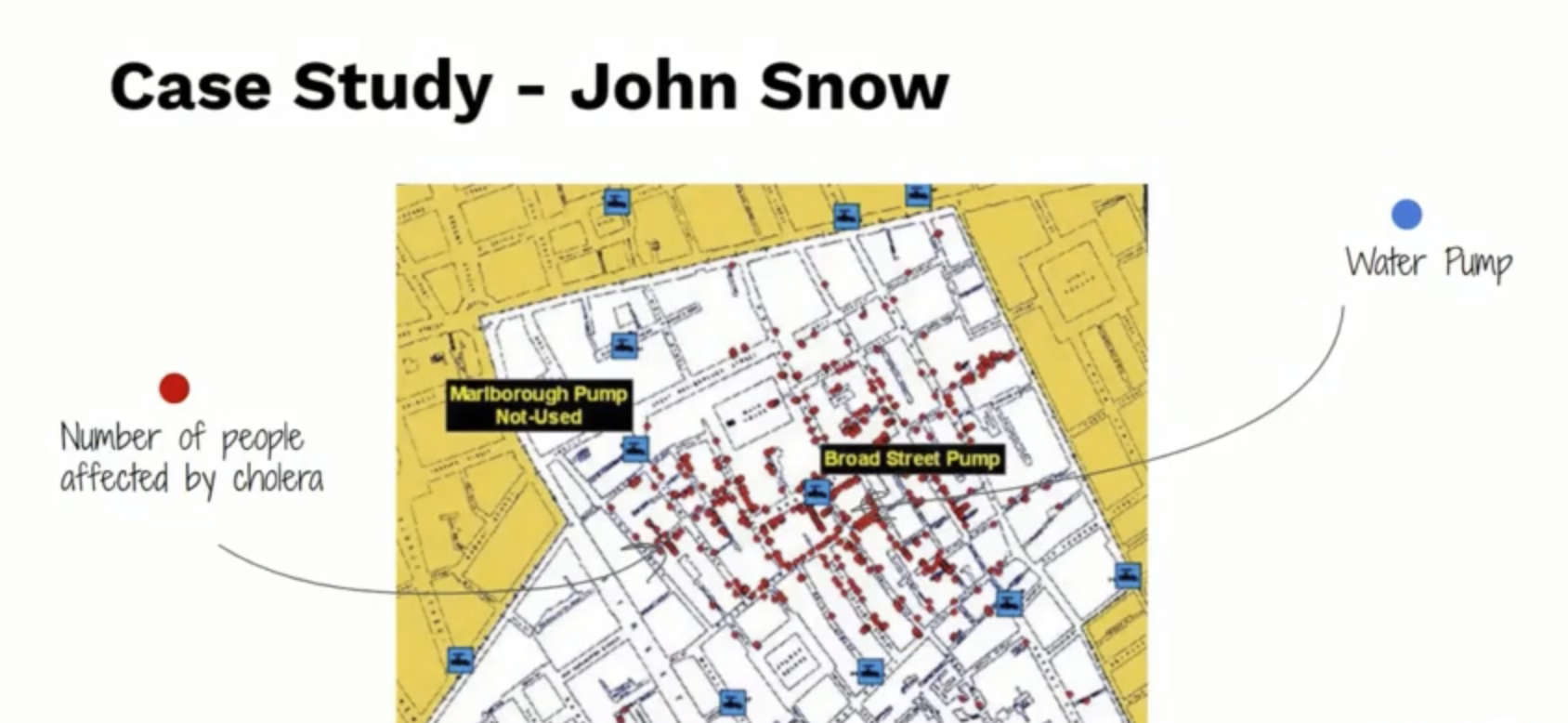
ใน case study นี้เป็นเหตุการณ์ของโรคอหิวาตกโรคในประเทศอังกฤษ ซึ่งมีคนตายเยอะมาก ดูจากจุดสีแดง ซึ่งเป็นการระบุตำแหน่งของผู้เสียชีวิตจากโรคอหิวาฯ โดยเหตุการณ์ช่วงนั้น ยังไม่รู้สาเหตุการตายของโรคแล้วสันนิฐานผิดคิดว่า เป็นเพราะการแพร่ระบาดทางอากาศ ถ้าใครที่เคยอ่านประวัติศาสตร์เรื่องนี้ ก็จะเคยเห็นหน้ากากลักษณะเหมือนปากอีกา แต่เป็นการสันนิฐานที่ผิด

Plague doctor costume - Wikipedia
ทาง John Snow ผู้ที่ไม่เชื่อเรื่องนี้ ก็เลยทำ แผนที่นี้ขึ้นมาเพื่อหาข้อเท็จจริง และสันนิฐานว่า ต้นเหตุของโรคระบาดน่าจะมาจากน้ำ หรือ อาหารที่กินเข้าไป โดยกำหนดจุดบ่อน้ำสำหรับบริโภคในสมัยนั้นขึ้น สรุปว่าเป็นจริงอย่างที่ John Snow สันนิฐานเอาไว้
Case Study แผนที่นี้เป็น case study ที่มักจะยกเอามาพูดคุยกันในเรื่องของการทำ Virtualization ซึ่งเพียงแค่การ plot graph ยังไม่มีเรื่อง การคำนวนค่าสถิติเข้ามาเกี่ยวข้อง ก็สามารถหา Value บางอย่างได้จากรูปภาพแล้ว ดังนั้น ก่อนจะเริ่มเล่นกับข้อมูล จะต้องสร้างกราฟเพื่อดูความสัมพันธ์เบื้องต้นก่อนเสมอ
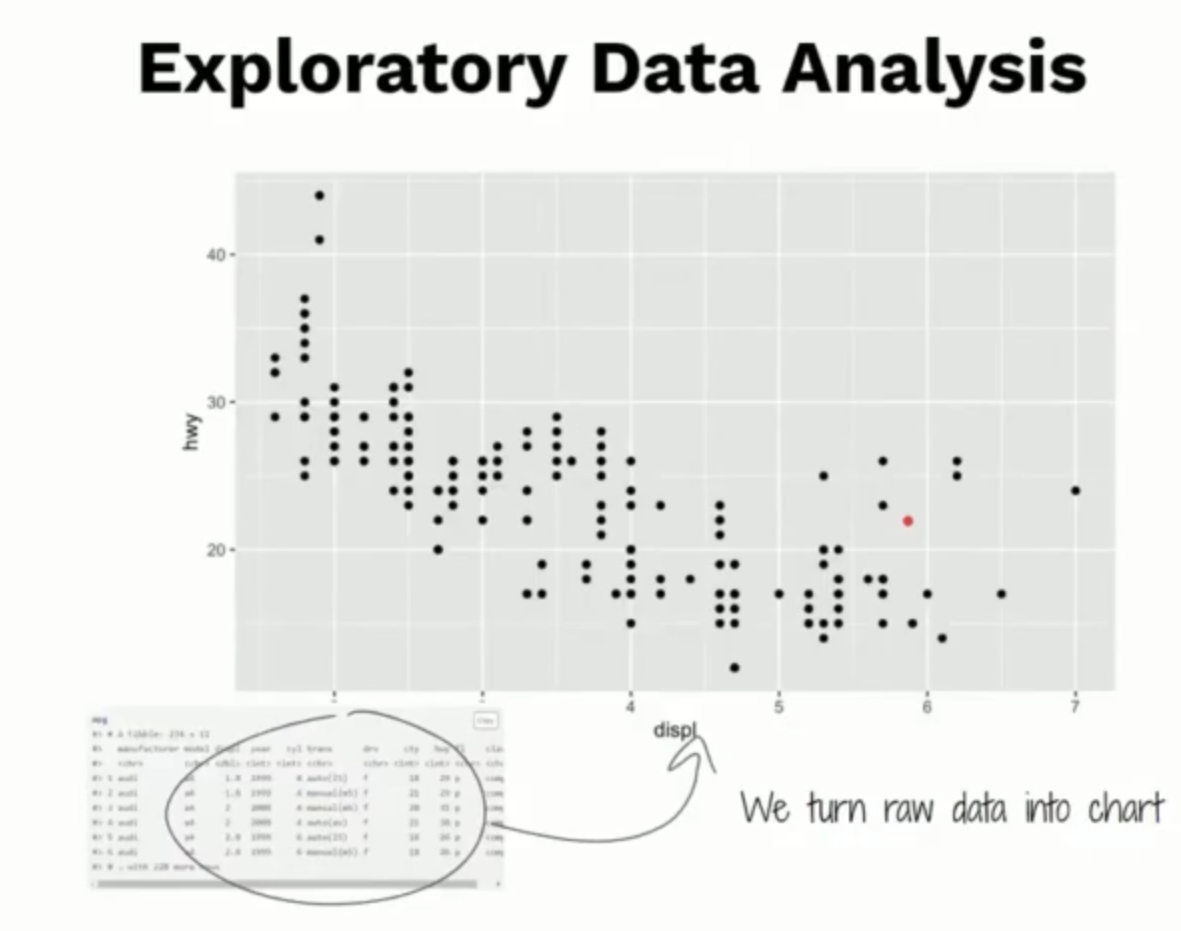
Exploratory Data Analysis (EDA)
เราจะแปลงข้อมูลจากตารางข้อมูลดิบ ซึ่งที่ดูไม่รู้เรื่อง อยู่ 2 วิธี
สิ่งที่เราจะทำในเบื้องต้นคือการทำ EDA เป็นการวิเคราะห์ข้อมูลเบื้องต้น
- การทำ Numerical Method เทคนิคทางตัวเลข เช่น
- การหาค่าทางสถิติ - sd, mean, correlation
- การทำ basic modeling - linear regression
- การทำ Graphic Method
เวลาเราเก็บข้อมูลมา แล้ว เปลี่ยนข้อมูลดิบให้เป็น รูปภาพก่อน
- ทำไว้ดูคนเดียวอาจจะไม่ต้องสวยมาก
- ทำให้คนอื่นดู ทำให้สวยขึ้น เพื่อเอาตีพิมพ์วิจัย หรือ พรีเซนงาน
ทำ Data Viz หรือ Data Virtualization บน RStudio
ลำดับแรกให้ติดตั้ง library บน RStudio ก่อน
install.packages("tidyverse")
แล้ว load library เพื่อ init ให้กับ Rstudio
library("tidyverse")
เพียงเท่านี้ก็เริ่มใช้งานได้เลย
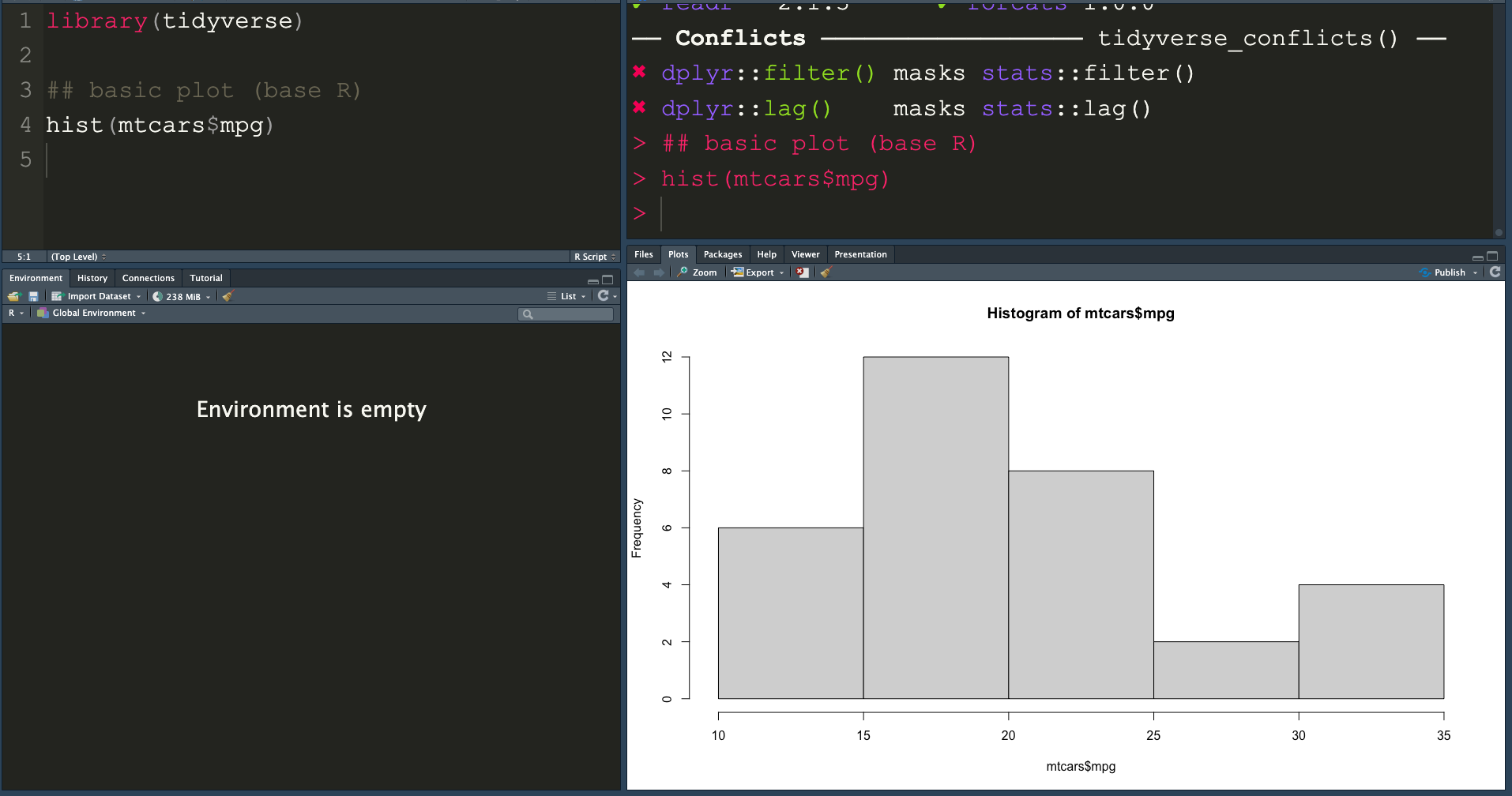
มาลองเล่นกับ Dataset - mtcars
Histogram
ให้เรียกคำสั่ง
hist(mycars$mpg
หรือลองดู แรงม้าของ dataset นี้ก็ได้
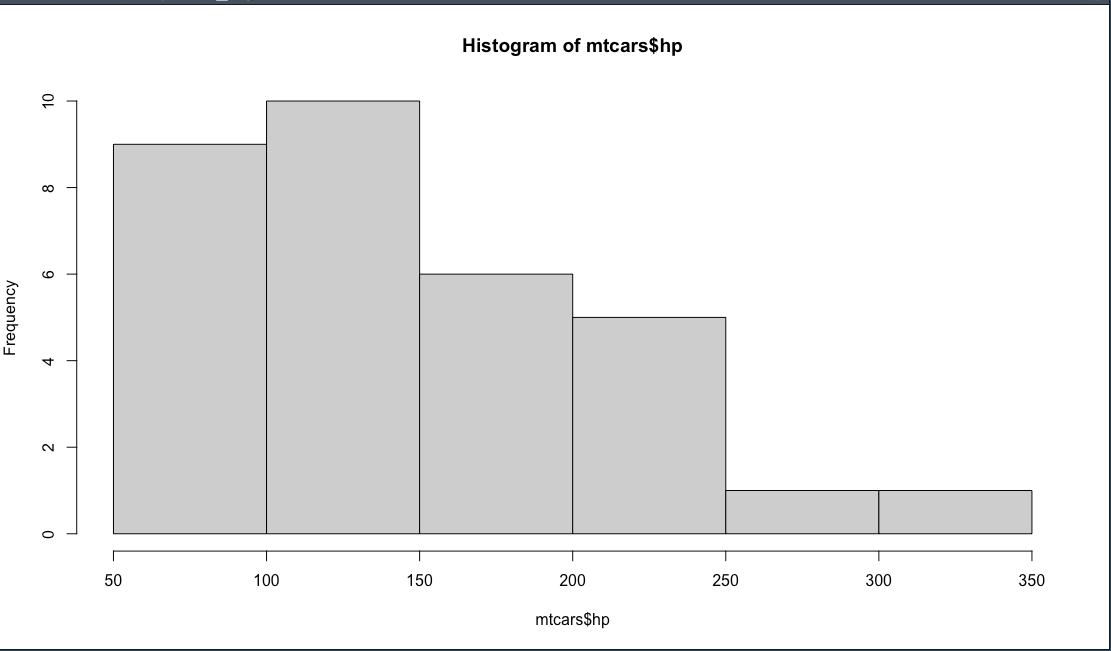
คราวนี้มาลองดูค่าเฉลี่ย ค่ากลาง เพราะเห็นว่าเกิด skew เบ้ขวา
เป็นการเช็คว่าข้อมูลเบ้ขวาจริงหรือไม่
## Analyzing horse power
## Histogram - One Quantitative Variable
hist(mtcars$hp)
mean(mtcars$hp)
median(mtcars$hp)
##
> mean(mtcars$hp)[1] 146.6875
> median(mtcars$hp)[1] 123
คราวนี้อยากจะลองดูข้อมูลอื่นๆดูบ้าง ให้ใช้คำสั่ง str (structure)เพื่อดูโครงสร้างของตารางหรือ data frame ว่ามีข้อมูลอย่างไร
str(mtcars)
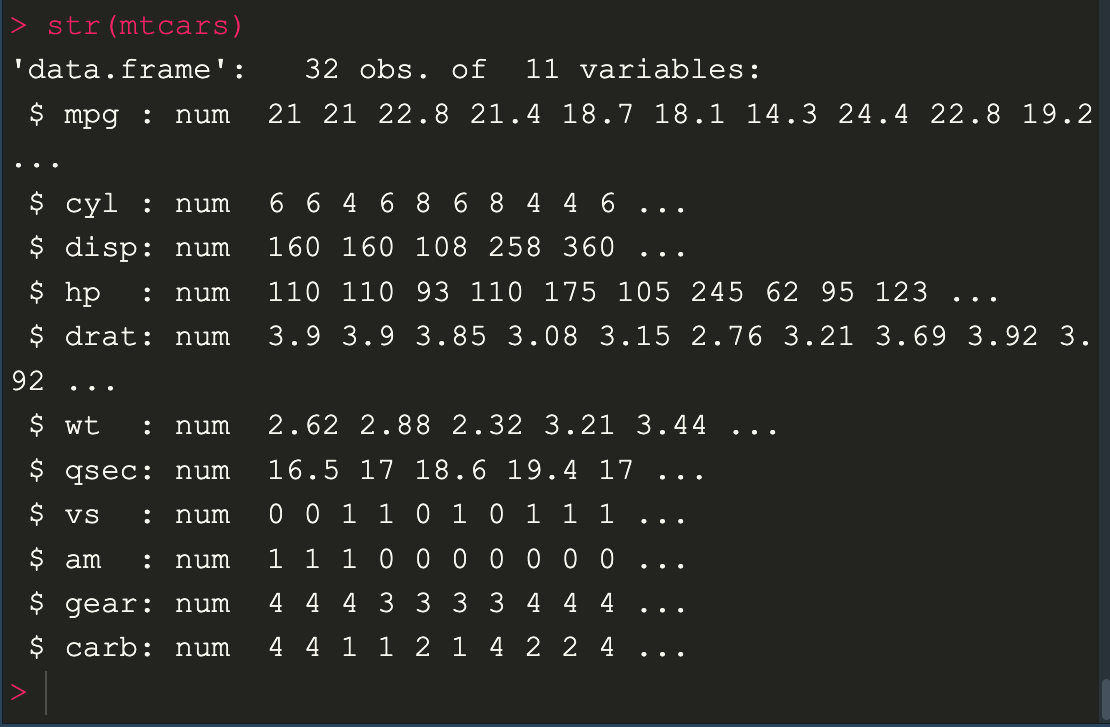
ลอง EDA คร่าว จะเห็นว่าข้อมูล data frame ทั้งหมดมีอยู่ 32 object 11 variable และทุกตัวเป็นตัวเลขทั้งหมด
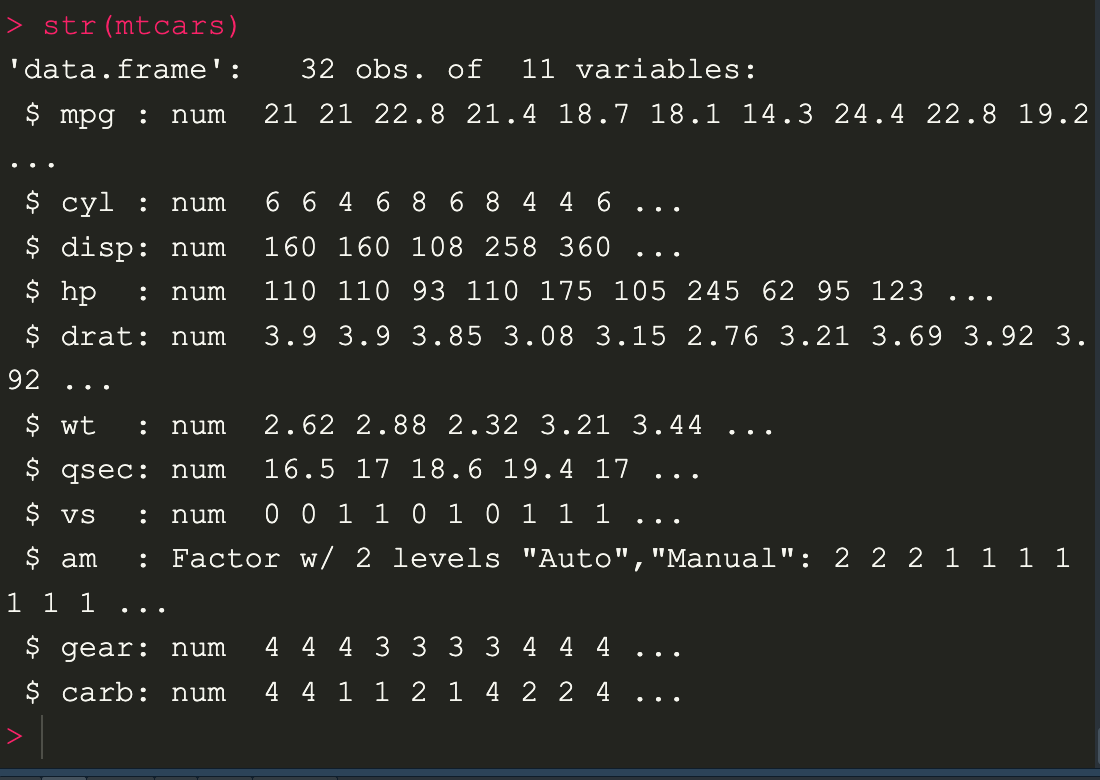
ทั้งนี้ต้องย้อนกลับไปดูข้อมูล data dictinary ด้วยว่า ตัวแปรแต่ละตัวหมายถึงอะไรบ้าง ซึ่ง ยกตัวอย่างตัวแปรที่ชื่อ am หมายถึง เกียร์แบบ manual ซึ่งจะมีแค่ค่า 0 และ 1 หมายความว่า 0 เป็นแบบ auto กับ 1 เป็นแบบ manual
Bar plot
เราสามารถเปลี่ยนค่า numeric ให้เป็นแบบ factor ได้ เพื่อจะทำให้เป็นข้อมูลเชิงคุณภาพ
mtcars$am <- factor(mtcars$am
, level = c(0,1)
, labels = c("Auto", "Manual"))
เป็นนำค่ามา convert แล้ว assign กลับเข้าไปใหม่ ก็จะเห็นว่าค่า am ได้เปลี่ยนไปแล้ว
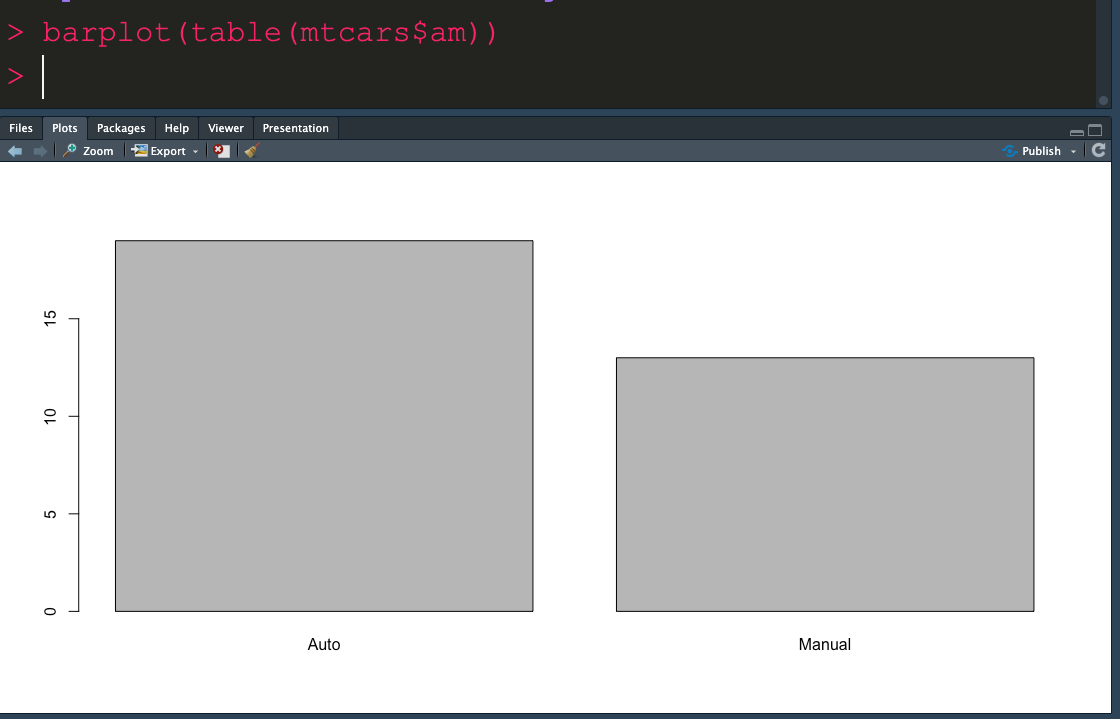
โดยเราจะนำค่า Factor มาแสดงผลด้วย Bar Plot
ในการจะนับ Counting ของ จำนวนใน Factor ว่ามีเท่าไรให้ใช้ คำสั่ง table ในการดูค่า
## Bar Plot - One Quanlitative Variable
table(mtcars$am)
#
Auto Manual
19 13
จะเห็นว่าค่า รถยนต์ที่เป็นชนิด Auto มีอยู่ 19 คัน และ manual 13 คัน
นำมา plot graph ด้วย bar plot
barplot(table(mtcars$am))
จะได้ผลลัพท์ออกมา
Box Plot
Box Plot ใช้เมื่อไรบ้าง
box plot สามารถนำไปใช้ได้หลากหลายข้อมูล อาจจะใช้ในข้อมูลที่เป็น 1 ตัวแปร หรือ มากกว่า 2 ตัวแปรก็ได้
เราจะนำ box plot มาวาดกราฟ mtcars เหมือนเดิม โดยใช้คำสั่ง
boxplot(mtcars$hp)
จะได้ผลลัพท์ดังนี้
สังเกตได้ว่า ข้อมูลจะถูกกำหนดเป็นช่วงที่อยู่ใน Range ระหว่าง เส้น 2 เส้น แต่จะเห็นว่ามี จุดกลมๆ อยู่ด้านบนสุด ตรงจุดนี้ เราจะเรียกว่า outlier
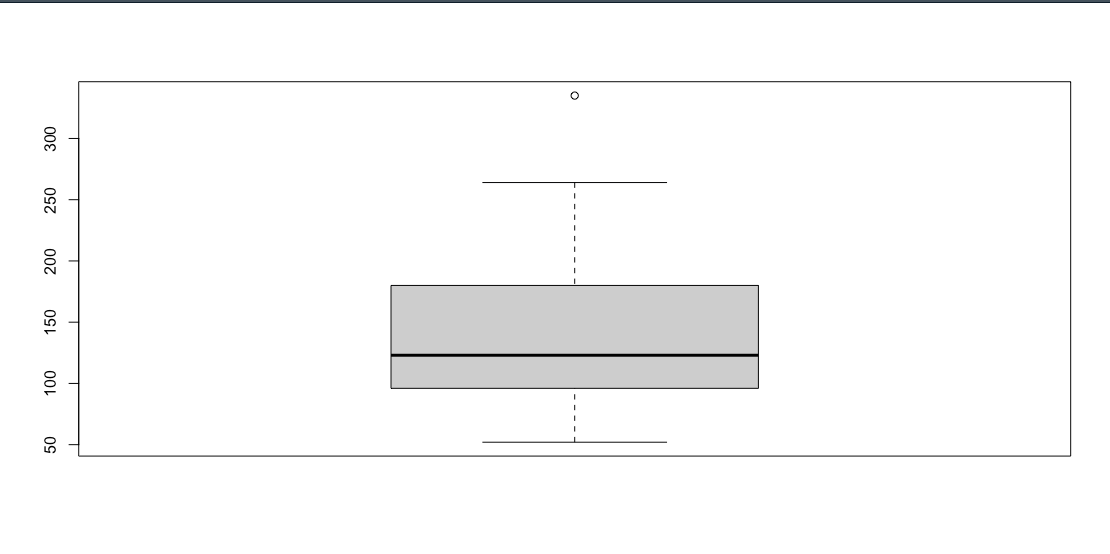
Outlier คืออะไร
ค่าบางค่าที่มีค่าสูงเกินไป ถ้ามองจากกราฟด้านบนนี้ สมมติว่าเป็นช่วงเงินเดือนของพนักงาน บริษัทไอทีแห่งหนึ่ง ช่วงประมาณ ไม่เกิน 50,000 บาท นั่งดื่มเหล้ากันในบาร์ แต่ว่าจุดกลมๆที่เรียกว่า Outlier คือ Bill Gate ที่มีเงินเดือน แสนล้านบาท เดินเข้ามานั่งดื่มด้วย พนักงานไอทีก็เลยให้ bill gate เลี้ยงเหล้าซะเลย เดี๋ยววว
five numver summery
ตัวเลข 5 ตัวที่เอาไว้สำหรับดูข้อมูลบน box plot
fivenum(mtcars$hp)
#
[1] 52 96 123 180 335
min, qualitile$1(ขอบกล่องด้านล่าง), qualtile$2 (median), qualtile$3(ขอบกล่องด้านบน), max (ที่แสดงเป็นค่า outlier)
หรือเขียนแบบนี้
min(mtcars$hp)
quantile(mtcars$hp, probs = c(.25, .5, .75))
max(mtcars$hp)
> min(mtcars$hp)
[1] 52
> quantile(mtcars$hp, probs = c(.25, .5, .75))
25% 50% 75%
96.5 123.0 180.0
> max(mtcars$hp)
[1] 335
แขนของ grap box plot
จาก box plot จะเห็นว่ามีเส้นปะ ที่ยื่นออกมาจากกล่อง เรียกว่า แขนของ box plot
คำถามคือ เราจะรู้ได้อย่างไรว่ามาจะยื่นออกมาแค่ไหน
มันมีวิธีคำนวน คือ
กล่อง box plot ขอบบน ถึง ขอบล่าง เราเรียกว่า IQR
IQR = Q3 - Q1
Q3 + 1.5 IQR ขอบบน
Q1 - 1.5 IQR ขอบล่าง
ถ้าเขียนด้วย R
Q3 <- quantile(mtcars$hp, probs = .75)
Q1 <- quantile(mtcars$hp, probs = .25)
IQR <- Q3 - Q1
ลองเช็คย้อนกลับด้วย fivenum โดยเอาค่า 75% -25%
> fivenum(mtcars$hp)
[1] 52 96 123 180 335
> 180 - 96
[1] 84>
IQR 75% 83.5
การคำนวนแขนด้านบน
Q3 + 1.5*IQR
การคำนวนแขนด้านล่าง
Q1 - 1.5*IQR
???? วิธีคำนวน แขนไม่ได้มีแค่วิธีเดียว
พอลองเอาการคำนวนแขนมาลอง Run ดู เมื่อเทียบจากกราฟที่ plot ออกมาแล้วดูแล้วไม่ค่อย make sense กับค่าที่ได้จริงๆ ดังนั้น ต้องลองหาฟังก์ชันที่มีคนทำไว้อยู่แล้วมาลองใช้งาน
ให้ลองเอา keyword ไปลองหาฟังก์ชัน
boxplot stat
ก็จะเจอฟังก์ชัน boxplot
ให้ลอง run ดู จะมีค่าต่างๆ พร้อมบอกค่า outlier ให้ด้วย
boxplot.stats(mtcars$hp, coef = 1.5)
###
$stats[1] 52 96 123 180 264
$n
[1] 32
$conf
[1] 99.5382 146.4618
$out
[1] 335
เวลาที่ต้องการ clear outlier ออกก็ให้ใช้ filter กำจัดแล้วนำค่าที่ได้มา plot graph ใหม่
## filter out outlier
mtcars_no_out <- mtcars %>% filter(hp < 335)
boxplot(mtcars_no_out$hp)
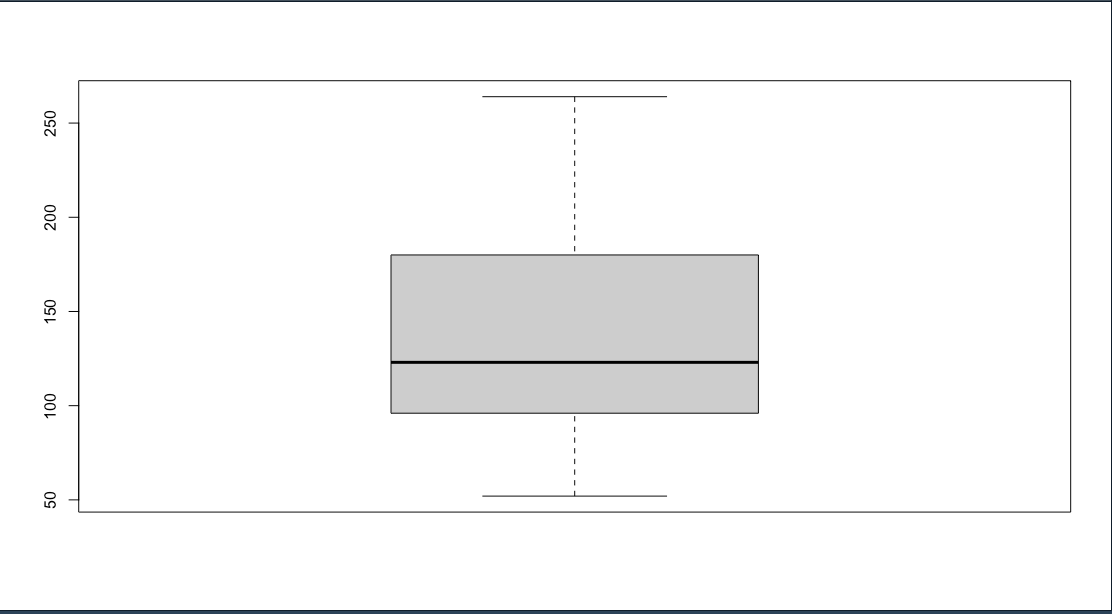
ประโยชน์ของ Boxplot สามารถใช้ตัวแปรสองตัวก็ได้ โดยที่ ตัวแปรที่ 1 จะเป็นชนิด quanlitative ตัวแปรที่ 2 จะเป็นชนิด quantitative
#Boxplot 2 Variable
## Qualitative x Quantitative
data(mtcars)
mtcars$am <- factor(mtcars$am, level = c(0,1),labels = c("Auto", "Manual"))
boxplot(mpg ~ am, data = mtcars)
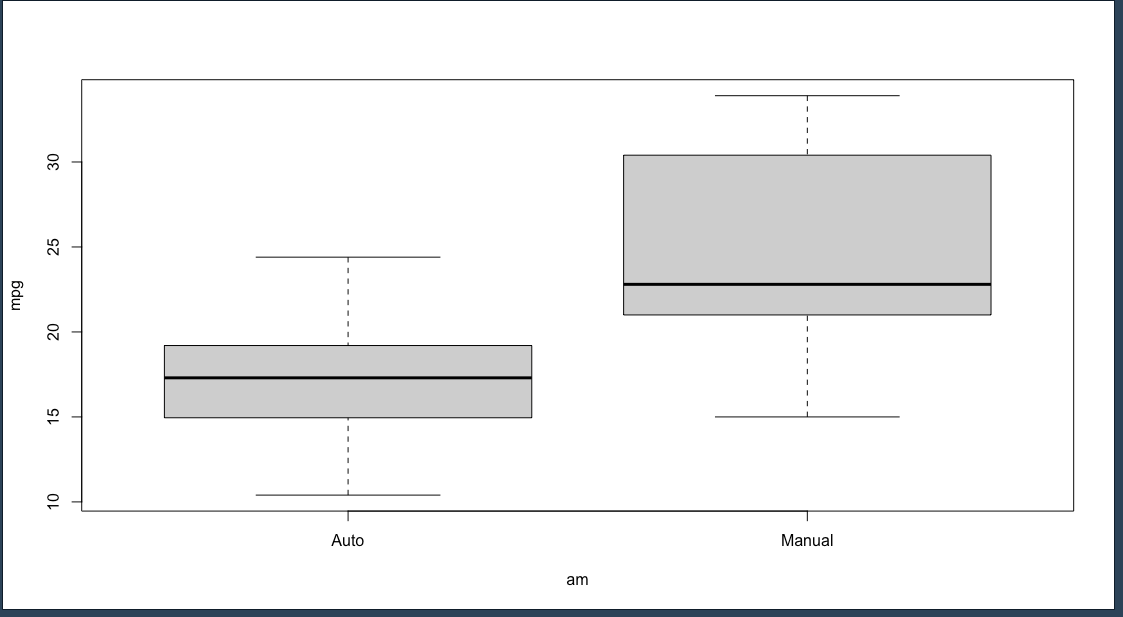
จากรูปภาพสังเกตว่า am จะเป็นแกน X และ mpg จะเป็นแกน Y โดยที่ฟังก์ชัน boxplot(Y ~ X, data) โดยแบ่ง ประเภท Auto และ Manual เอาไว้ด้วย
ลองตั้งคำถาม
ลองสังเกตว่า รถยนต์ประเภทใดที่มี mpg สูงกว่า ลองดูที่ median ก็ได้
คำตอบคือ Manual เพราะ median มากกว่าอย่างชัดเจนในกราฟ
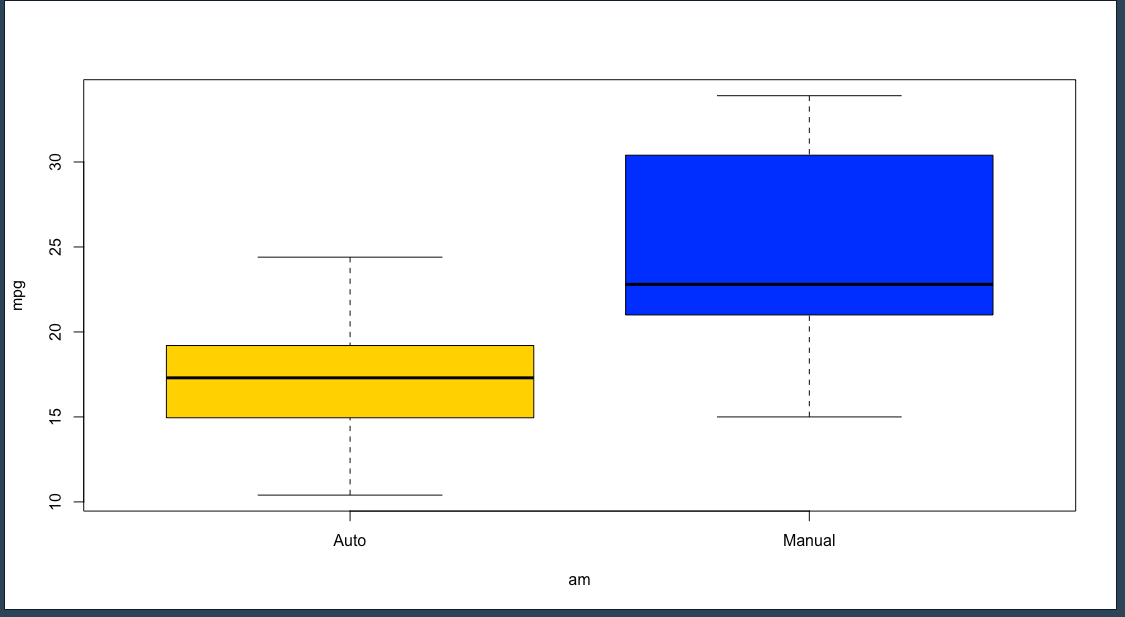
ฟังก์ชัน boxplot สามารถใส่สีเพื่อแยกประเภทให้เห็นชัดเจนขึ้นได้ โดยกำหนด argument ชื่อว่า col เข้าไป
boxplot(mpg ~ am, data = mtcars, col = c("gold", "blue")
Scatter plot
จะใช้กับ 2 ตัวแปร แบบ quantitative
โดยการใช้ คำสั่ง
plot(mtcars$hp, mtcars$mpg)
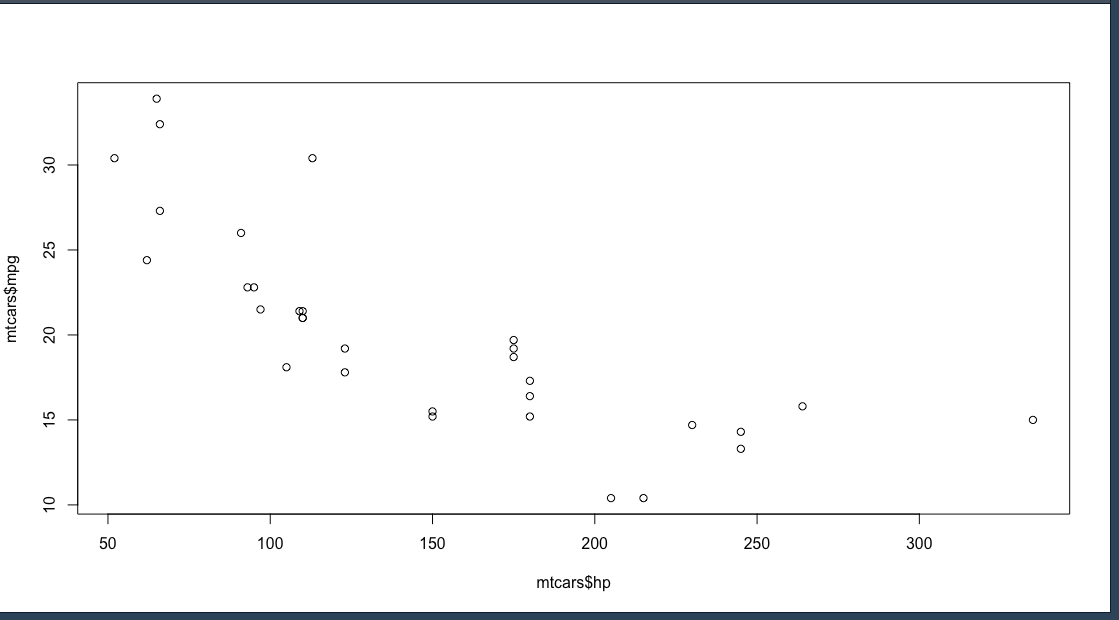
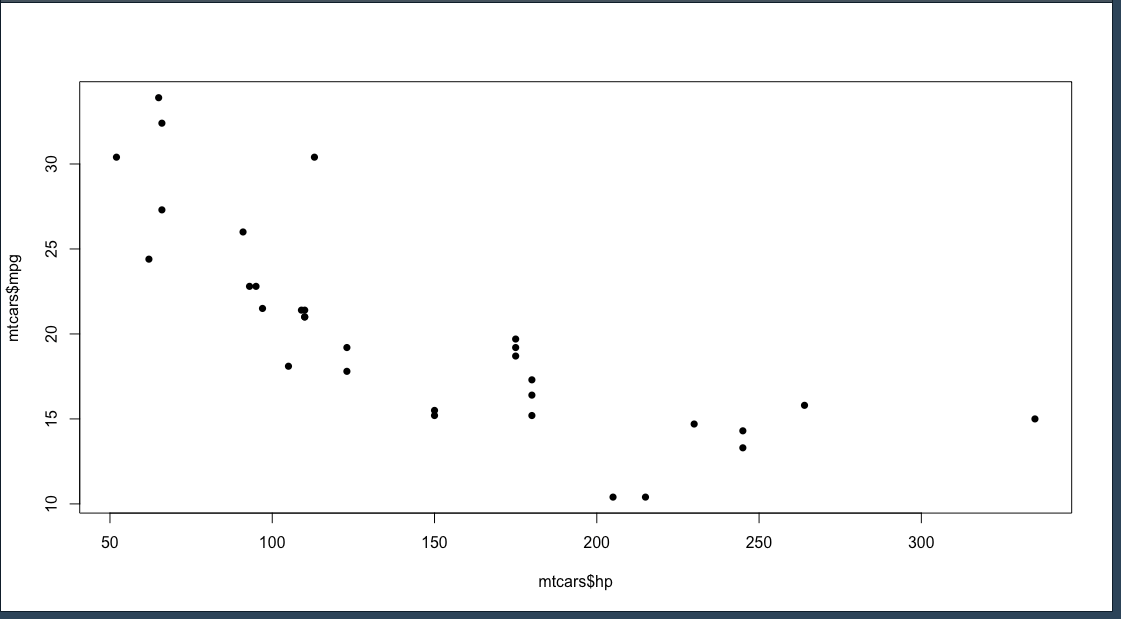
ถ้าเราต้องการจะเปลี่ยนรูปแบบการ plot ให้เพิ่ม argument pch แล้วใส่หมายเลขที่ต้องการ
plot(mtcars$hp, mtcars$mpg, pch = 16)
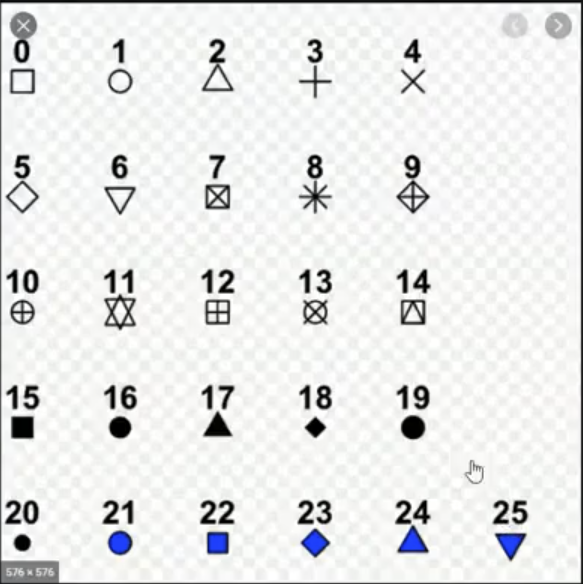
สามารถดู pch ได้จากตารางนี้
ทำให้มีสีเพิ่มขึ้น
plot(mtcars$hp, mtcars$mpg , pch = 16, col = "red")
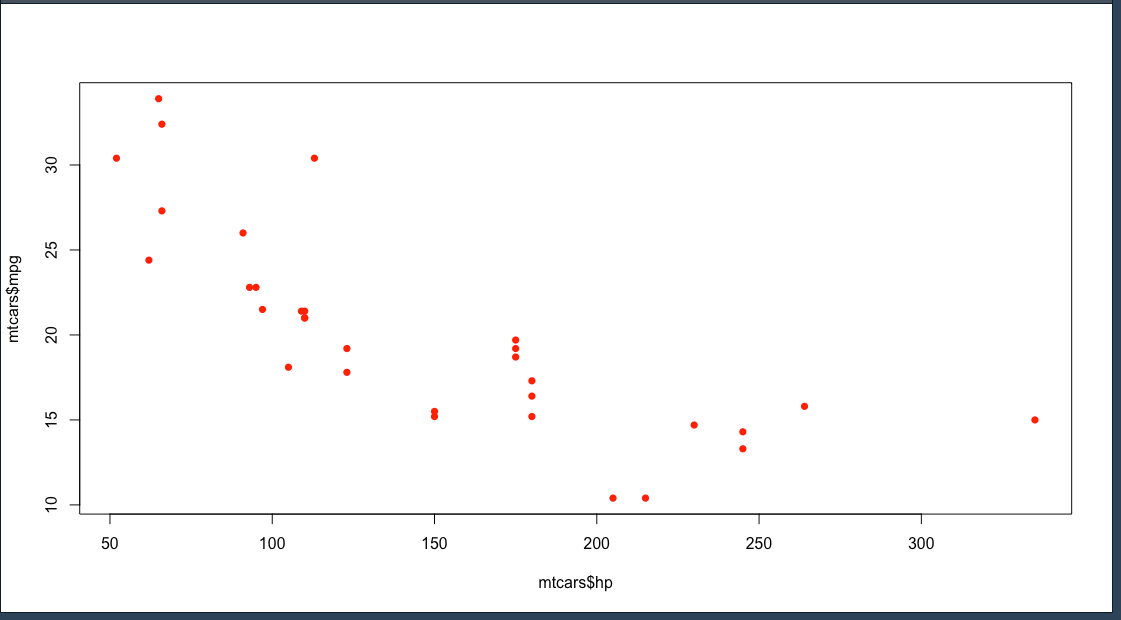
ถ้าสังเกตค่า ความสัมพันธ์ หรือ correlation จะเห็นว่าเมื่อ hp เพิ่มสูงขึ้น mpg จะลดลง แสดงว่าค่า R^2 ต้องติดลบ
เราสามารถดูค่า correlation ได้
> cor(mtcars$hp, mtcars$mpg)
## [1] -0.7761684
หรือใช้ linear regression
lm(mpg ~ hp, data = mtcars)
##
Coefficients:
(Intercept) hp
30.09886 -0.06823
GGPlot library
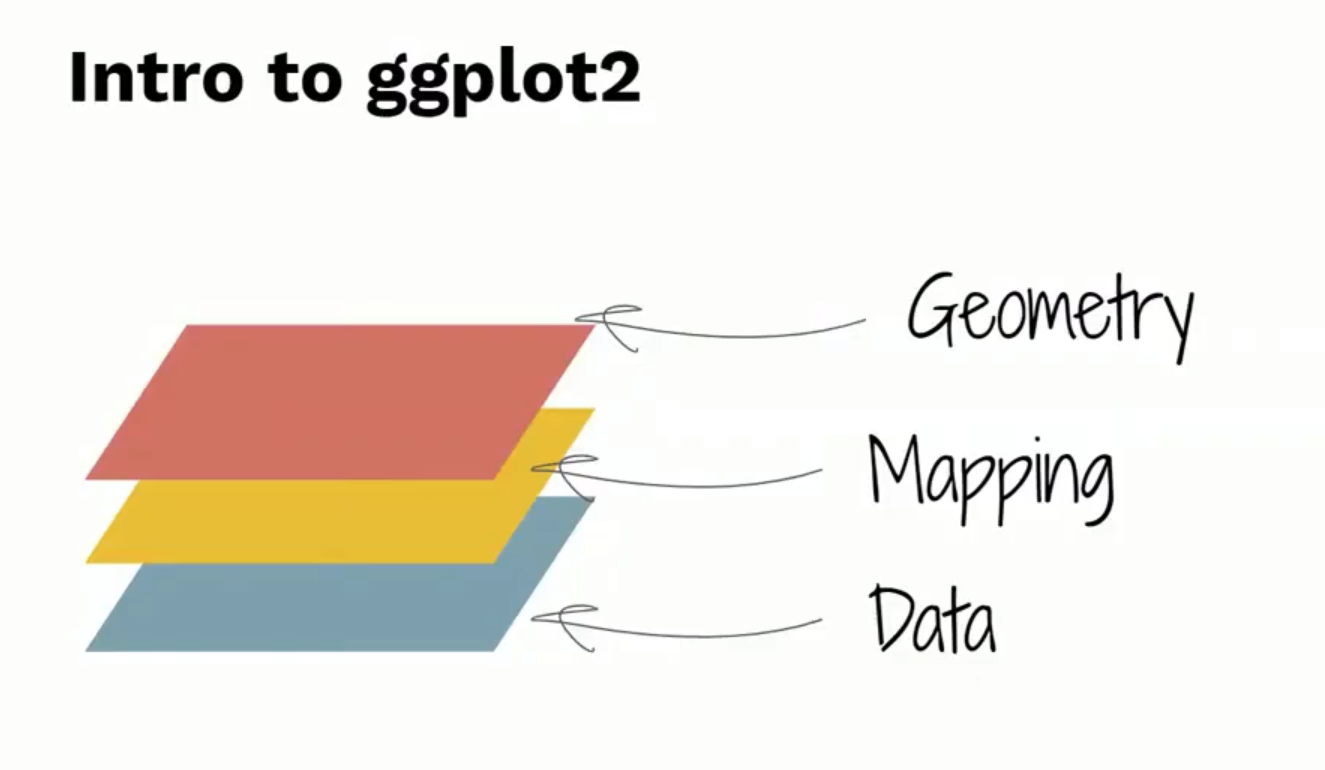
ggplot ย่อมาจาก Grammar of Graphic plot
ต้องการ 3 require
- Data
- Mapping
- Geometry
Data คือ dataset ของข้อมูลที่ต้องการ plot graph
Mapping คือ การดึง column จาก dataframe เพื่อที่จะ map ไปยัง chart
Geometry คือ รูปแบบ การแสดงผล
ggplot(data= …, mapping = … , geom_…())
สามารถ generate ไป 30 แบบ
https://www.maths.usyd.edu.au/u/UG/SM/STAT3022/r/current/Misc/data-visualization-2.1.pdf


วิธีการเลือกใช้ chart
- เรามีกี่ตัวแปร 1, 2 หรือ 3 ตัวแปร
- ประเภทของข้อมูล quanlitative หรือ Discrete (factor) , quantitative หรือ Continuous (numeric)
มาลองเริ่ม plot graph ด้วย ggplot ซึ่งจะสวยกว่า การ plot ที่ผ่านมา
ทำ initial ด้วย code ด้านล่างนี้ก่อน
##ggplot##
library(tidyverse)
## first plot
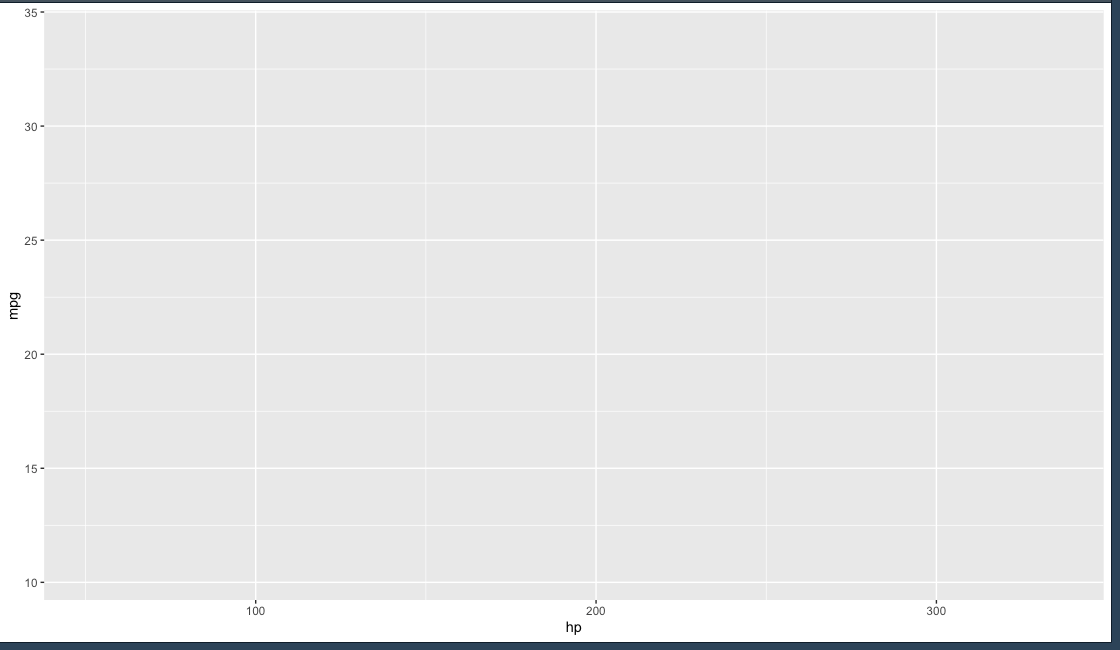
ggplot(data = mtcars,
mapping = aes(
x = hp,
y = mpg
))
จะได้ กราฟเปล่าๆออกมา
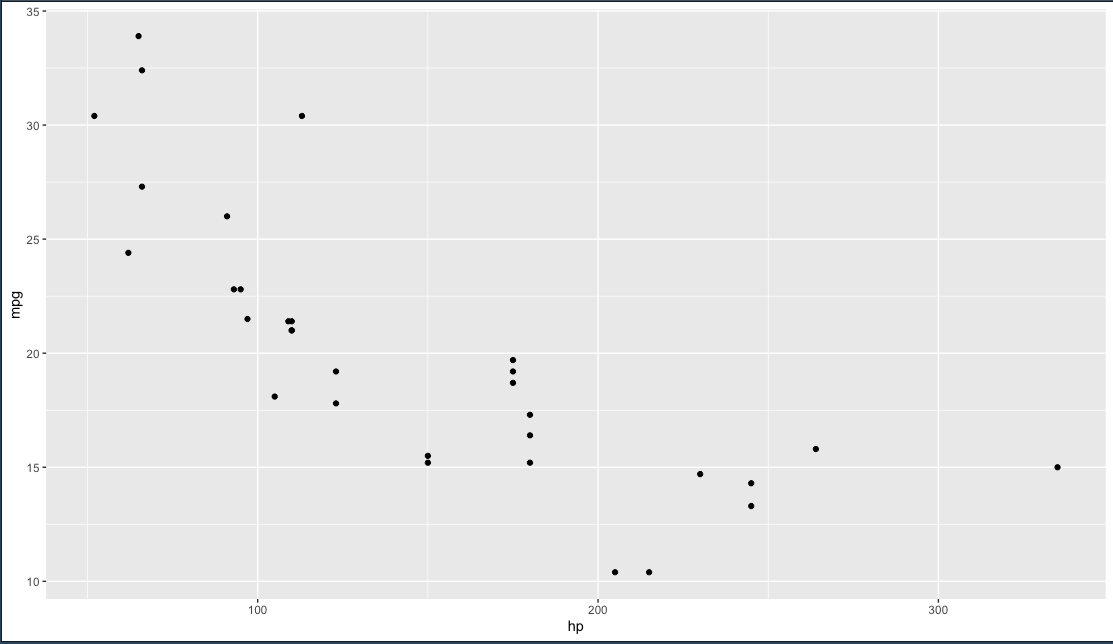
คราวนี้จะเลือกการแสดงผล โดยเพิ่ม รูปแบบที่ต้องการต่อท้ายเข้าไปด้วยเครื่องหมายบวก
geom_point การ plot แบบจุด 2 ตัวแปร
## first plot
ggplot(data = mtcars,
mapping = aes(
x = hp,
y = mpg
)) + geom_point()
ข้อมูลก็จะออกมาบนกราฟ 1 layer ตามภาพด้านล่างนี้
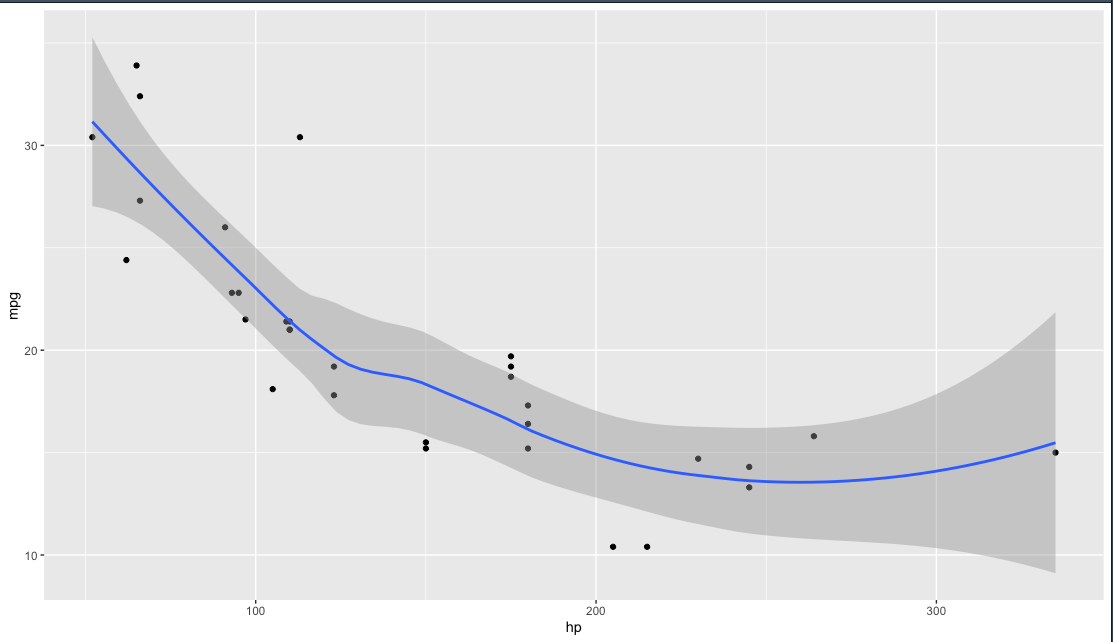
เราสามารถสร้างให้มีมากกว่า 1 layer ได้โดยเพิ่ม รูปแบบเพิ่มเข้าไป
## first plot
ggplot(data = mtcars,
mapping = aes(
x = hp,
y = mpg
)) + geom_point() + geom_smooth()
จะเห็นว่ามีอีก 1 layer เป็น 2 layer
ยังไม่หมดเท่านี้
## first plot
ggplot(data = mtcars,
mapping = aes(
x = hp,
y = mpg
)) + geom_point() + geom_smooth() + geom_rug()
geom_rug เอาไว้ดูความหนาแน่น
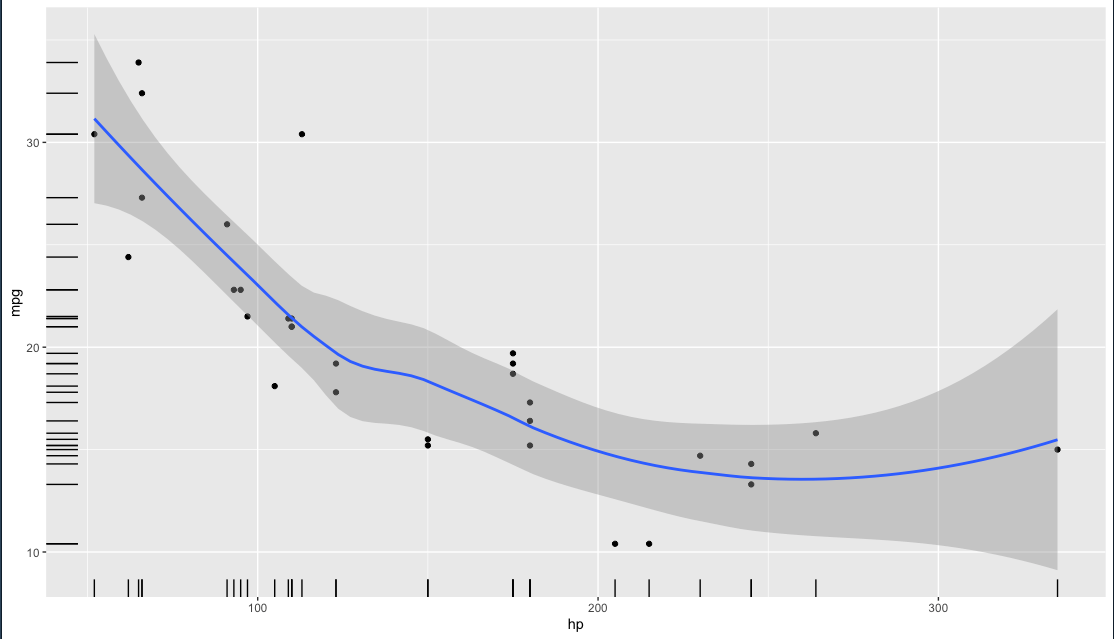
จาก code ทั้งหมดที่ผ่านมาเราไม่จำเป็นที่จะต้องใส่ ชื่อ argument ก็ได้
ggplot(mtcars, aes(hp, mpg)) + geom_point() + geom_smooth() + geom_rug()
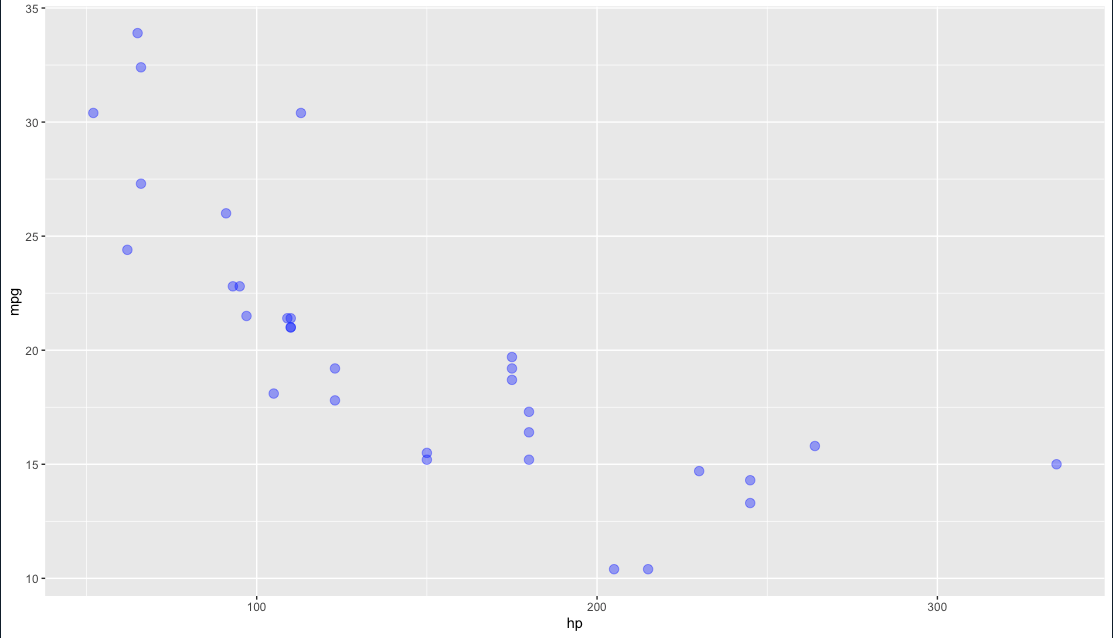
เราสามารถใส่ attribute ต่างๆได้
ggplot(mtcars, aes(hp, mpg)) + geom_point(size = 3, col = "blue", alpha = 0.2)
size : ขนาดของ จุด
col : สีของจุด
alpha : ความโปร่งใสของจุด
geom_histogram การ plot ค่า 1 ตัวแปร
ggplot(mtcars, aes(hp)) + geom_histogram(bins = 10, fill = "red")
bins : ค่า range ของข้อมูลแต่ละแท่ง
fill : การใส่สีให้กับแท่งกราฟ
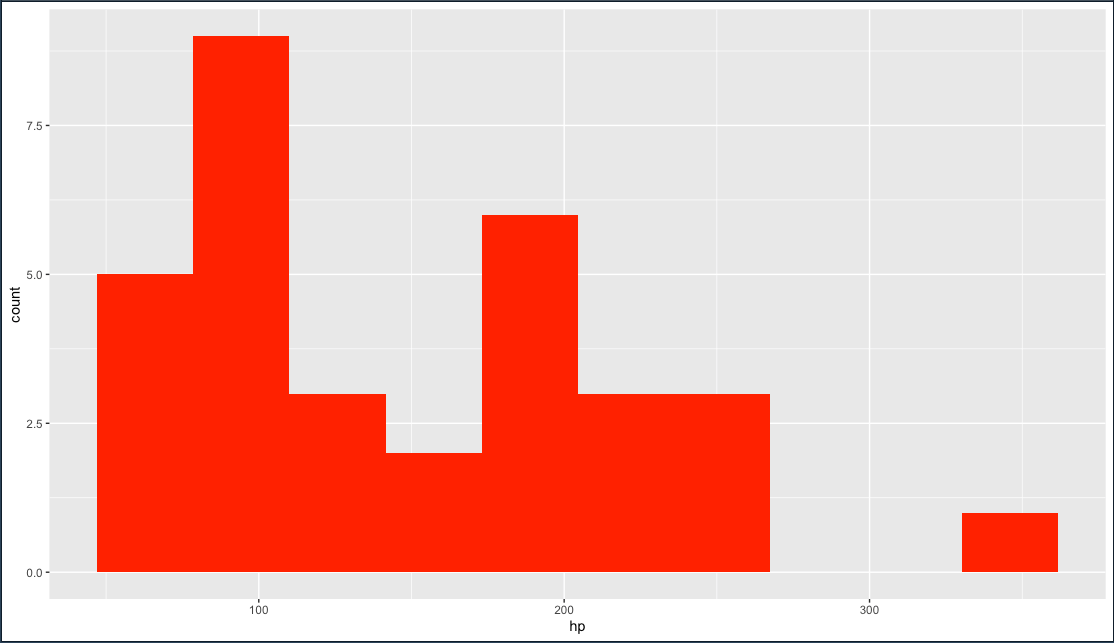
เวลาเลือก bins ให้เลือกให้เหมาะสมเพื่อจะได้เห็น plattern กับการแสดงผล เพราะการแสดงผลมันขึ้นอยู่กับ data ที่เราทำงาน
geom_boxplot
ggplot(mtcars, aes(hp)) + geom_boxplot()
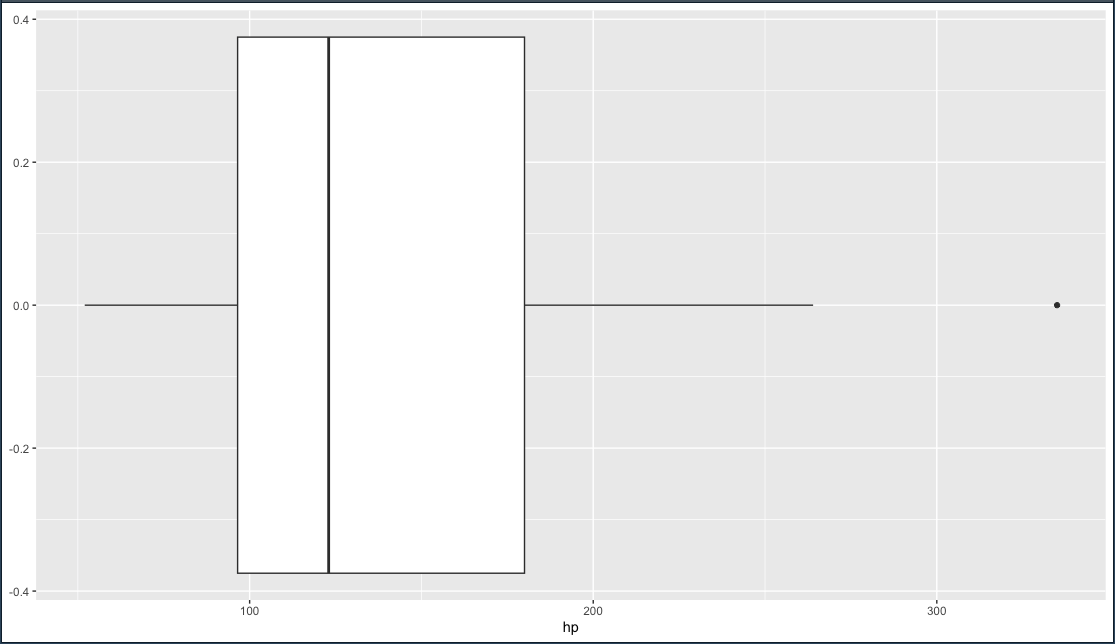
การสร้าง Object ให้กับกราฟ
เราสามารถ เก็บการ plot เอาไว้ในตัวแปรได้
p <- ggplot(mtcars, aes(hp))
นำมาใช้ โดยเอา object ที่สร้างขึ้นมาแสดงกราฟต่อเช่น
p + + geom_histogram(bins = 10, fill = "red")
สร้าง plot แบบ Group 2 ตัวแปร
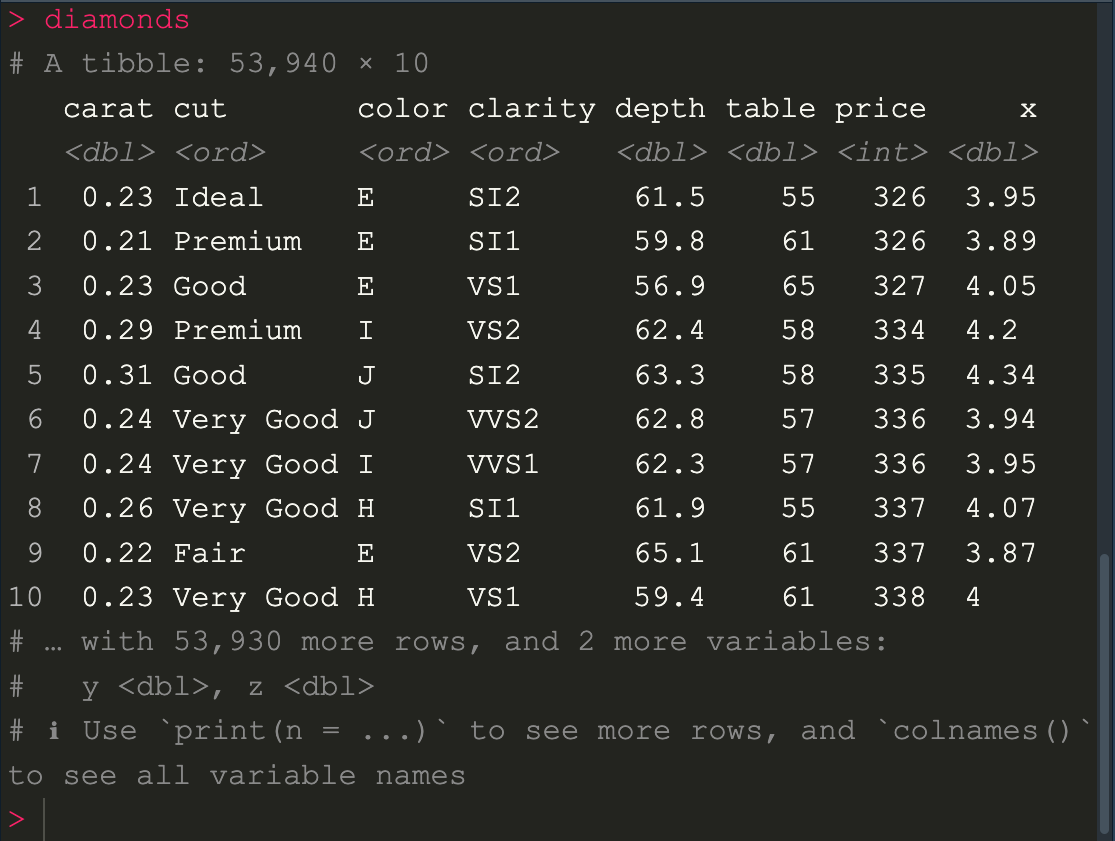
โดยเปลี่ยน dataframe ให้ใหญ่ขึ้น ให้ลองใช้คำสั่ง diamonds dataset เป็นข้อมูลเพชร เพื่อจะเอามา plot เป็น plot 2 ตัวแปร ซึ่งจะเป็นประเภท tribble
diamonds
คราวนี้เราจะทำการ filter ข้อมูล โดย transform data
diamonds %>% count(cut)
###
# A tibble: 5 × 2
cut n
<ord> <int>
1 Fair 1610
2 Good 4906
3 Very Good 12082
4 Premium 13791
5 Ideal 21551
เราจะเอา ข้อมูลชุดนี้มาทำเป็น bar plot ก่อน
ggplot(diamonds, aes(cut)) + geom_bar()
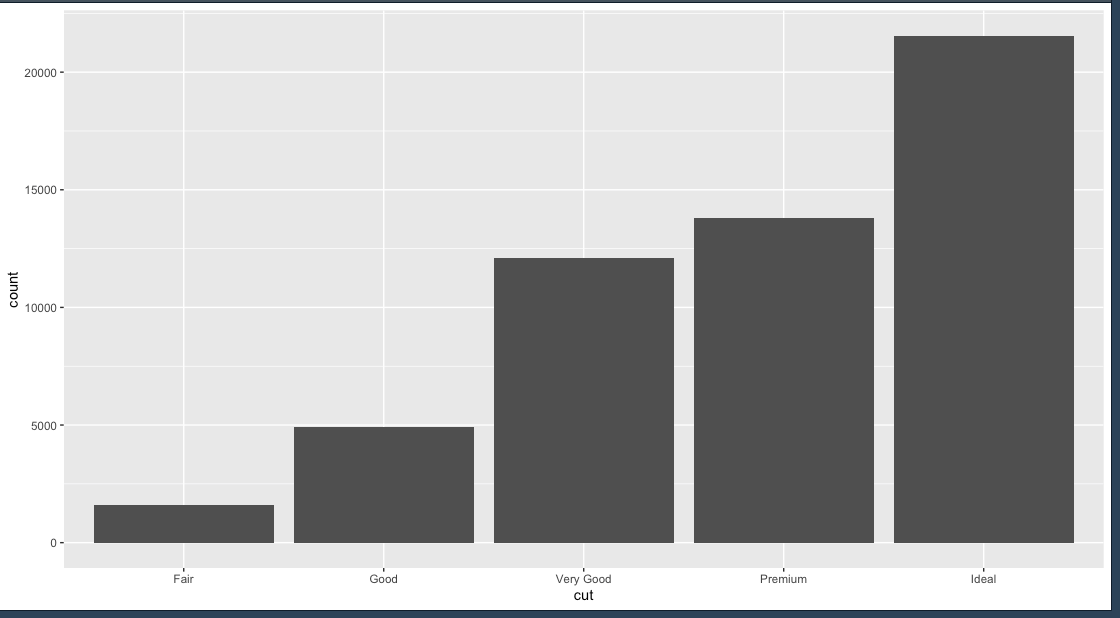
เหตุผลที่ให้ลองทำ bar plot ดูก่อน ก็เพื่อจะไปต่อยอดเป็น boxplot
ให้ count ข้อมูล จำนวนครั้งของสีเม็ดเพชร ว่าแต่ละเกรดมีจำนวนเท่าไรที่ column color ของ diamonds dataset สี D คือ แย่สุด สี J คือ ดีสุด มีอยู่ทั้งหมด 7 สี
diamonds %>% count(color)
###
# A tibble: 7 × 2
color n
<ord> <int>
1 D 6775
2 E 9797
3 F 9542
4 G 11292
5 H 8304
6 I 5422
7 J 2808
โดยที่สิ่งที่จะทำคือ จะเอาสีของ diamonds ไป map กับกราฟ bar plot เมื่อสักครู่นี้โดยเขียนคำสั่งแบบนี้
ซึ่งจะต้องทำใน mapping ก็คือใส่ dataframe ลงไปแต่ละแกน ของ aes(X, Y) เช่น cut คือ แกน X และ fill คือ แกน Y
ggplot(diamonds, mapping = aes(cut, fill=color)) + geom_bar()
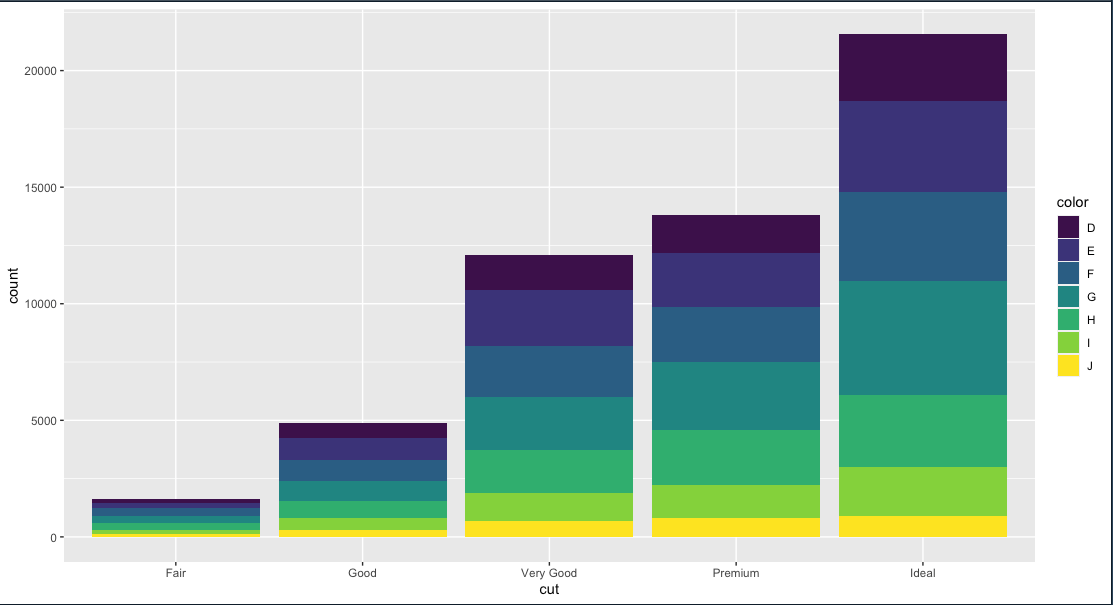
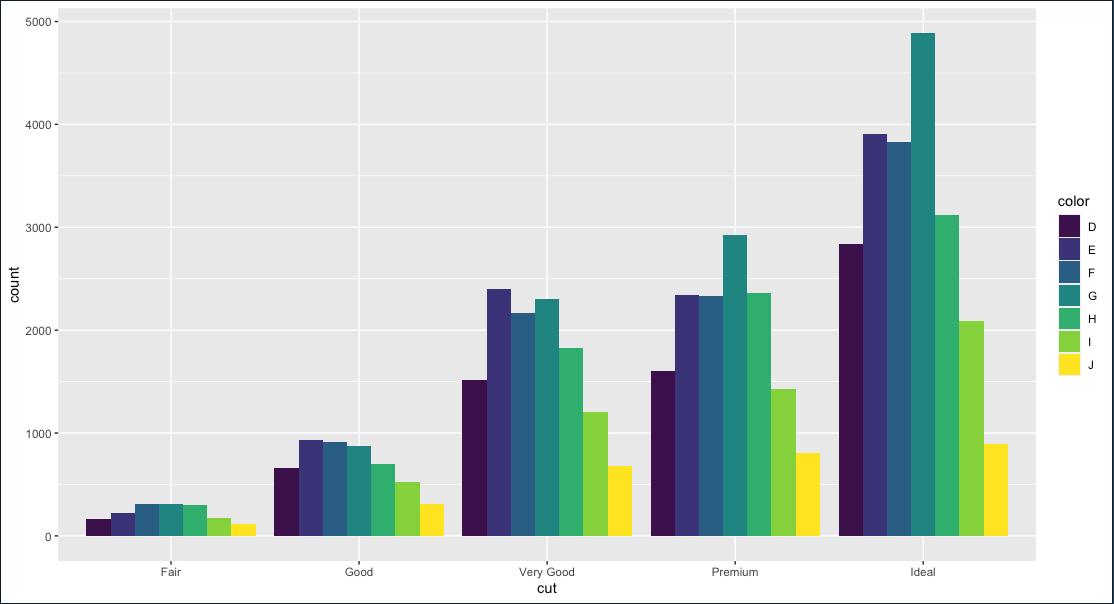
เราสามารถแก้ไขให้การแสดงผลในรูปแบบที่เราต้องการ ว่าต้องการจะแสดงตำแหน่งแบบไหน โดยกำหนด attribute ของ bar plot
ggplot(diamonds, mapping = aes(cut, fill=color)) + geom_bar(position = "dodge")
สร้าง Plot 2 ตัวแปรด้วยข้อมูลตัวเลข ด้วย Scatter plot
โดยใช้ข้อมูล carat และ price
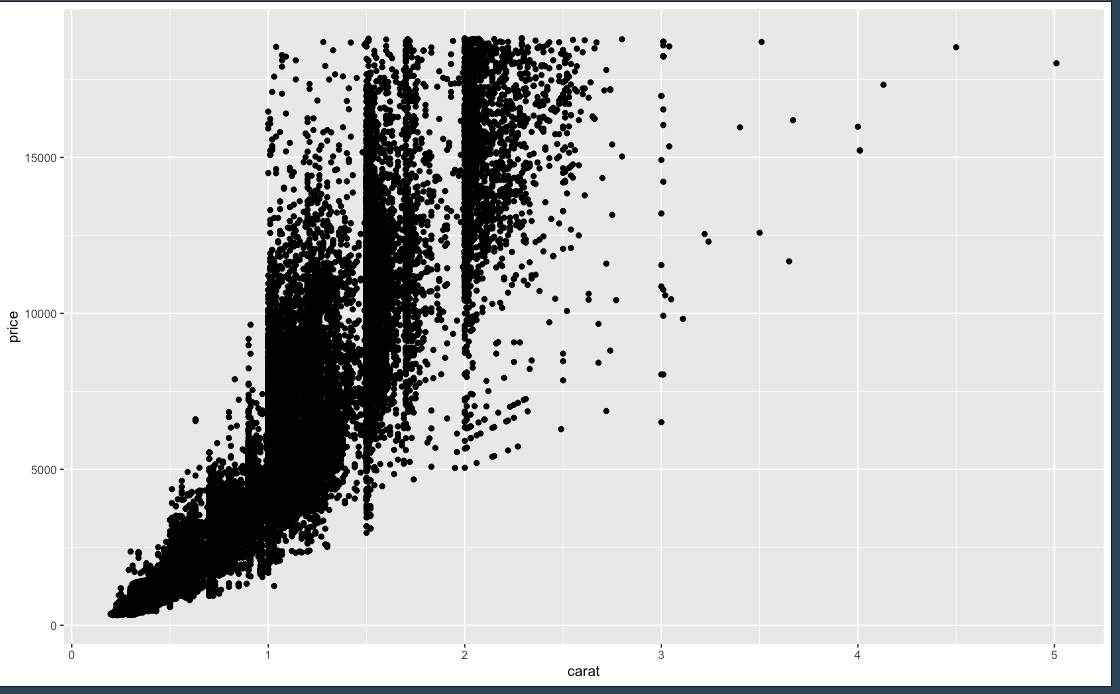
ggplot(diamonds, mapping = aes(carat, price)) + geom_point()
จะเห็นว่าข้อมูลที่ได้จาก diamonds dataset นี้ ค่อนข้างใหญ่ ดังนั้นอาจจะทำให้การ Render ข้อมูลเป็นกราฟอาจจะใช้เวลานาน ซึ่ง เราสามารถทำการ sample หรือ สุ่มข้อมูลจาก dataset มา plot กราฟได้
Scatter plot ที่นำข้อมูลทั้งหมด มา plot
Scatter plot ที่นำข้อมูลแบบ sample มา plot
## Sample
small_diamonds <- sample_n(diamonds, 5000)
ggplot(small_diamonds, mapping = aes(carat, price)) + geom_point()
เนื่องจาก plattern ไม่ได้ต่างกันมากระหว่าง ข้อมูลทั้งหมด กับ แบบสุ่มข้อมูล นี่คือเทคนิคของนักสถิติ
เราใช้ข้อมูลไม่ต้องเยอะ เราก็ได้ plattern แล้ว
FACET : small multiple concept
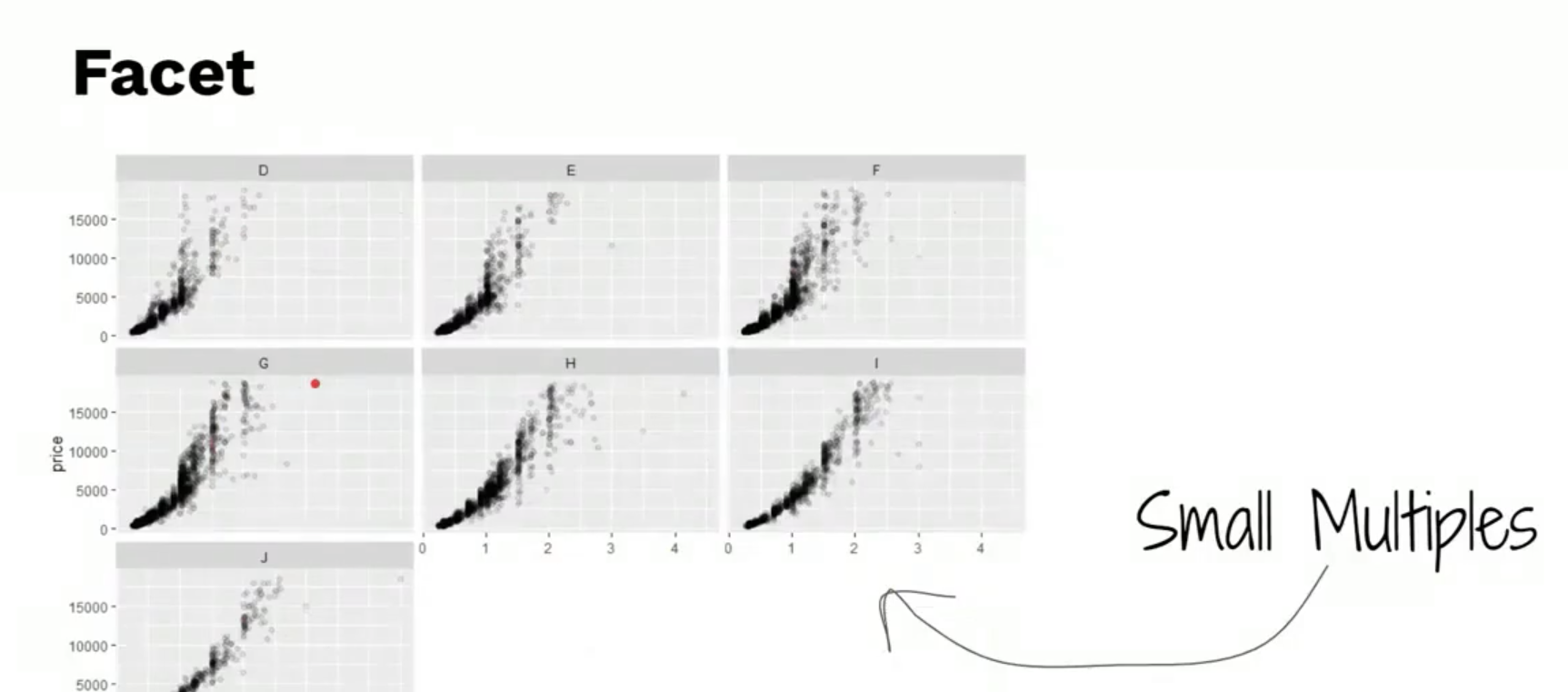
จากข้อมูลทั้งหมดของ dataset คือ 50,000 แล้วเราสุ่มมา 5000
เราสามารถที่จะ ซอยย่อยข้อมูลเป็นกลุ่มๆ ได้
โดยจากตัวอย่างด้านล่าง จะแบ่งเป็น 7 กลุ่ม ตาม สีของเพชร
facet มีอยู่ 2 แบบ
- facet_grid
- facet_wrap
facet wrap
small_diamonds <- sample_n(diamonds, 5000)
ggplot(small_diamonds, mapping = aes(carat, price)) + geom_point() + facet_wrap(~color)
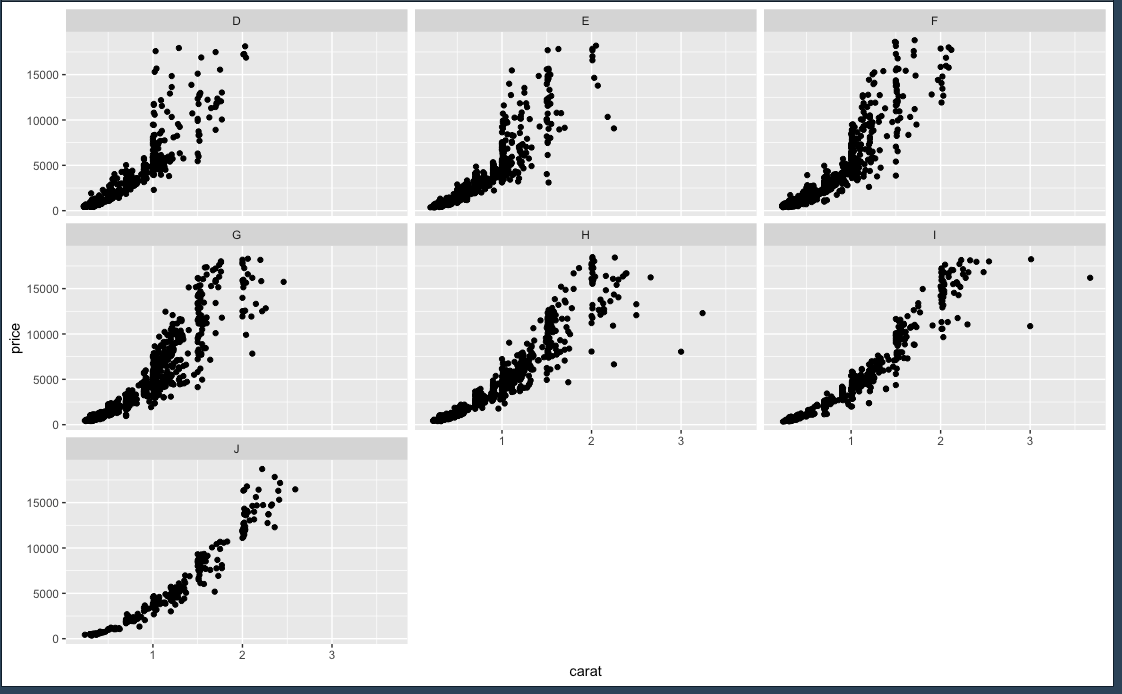
จัดวางแบบ column ได้ด้วย
small_diamonds <- sample_n(diamonds, 5000)
ggplot(small_diamonds, mapping = aes(carat, price)) + geom_point() + facet_wrap(~color, ncol=2)
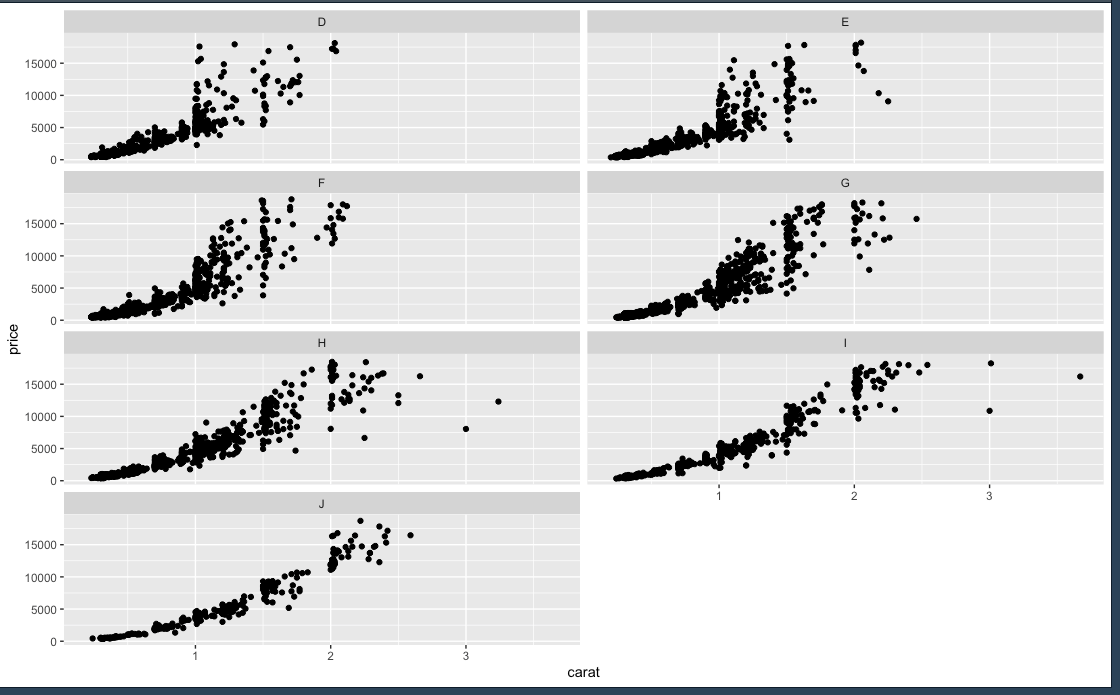
สามารถทื่ mapping สีได้ด้วย โดยสีน้ำเงินจะเป็น default
small_diamonds <- sample_n(diamonds, 5000)
ggplot(small_diamonds, mapping = aes(carat, price)) + geom_point() + geom_smooth(method = "lm") + facet_wrap(~color, ncol=2)
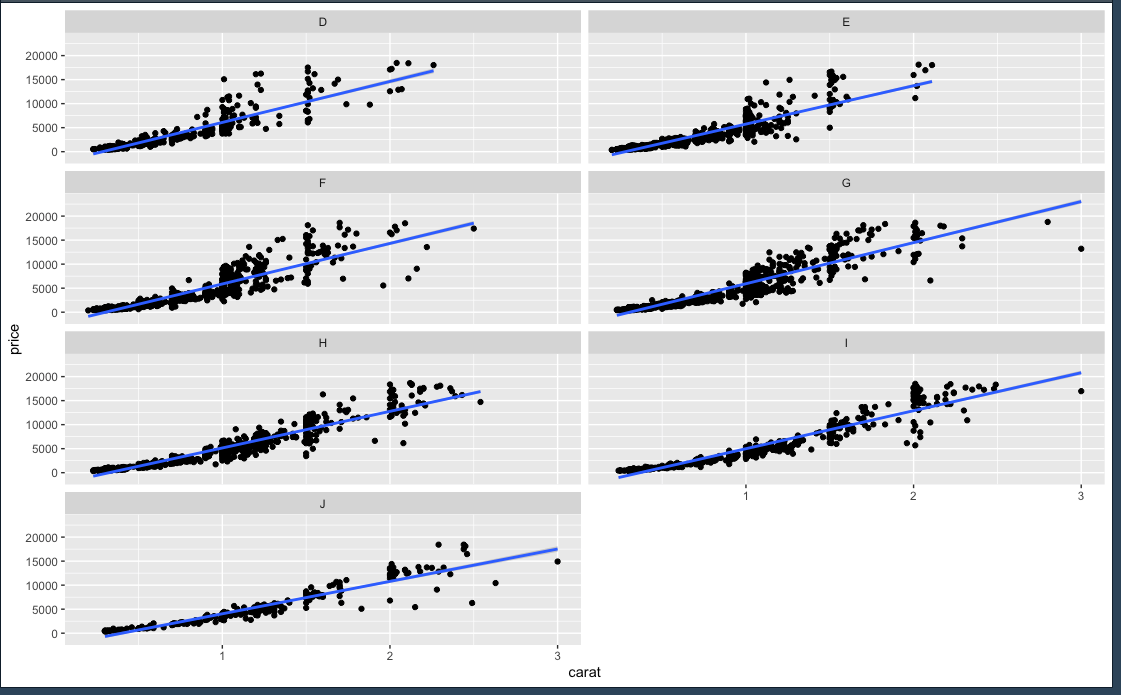
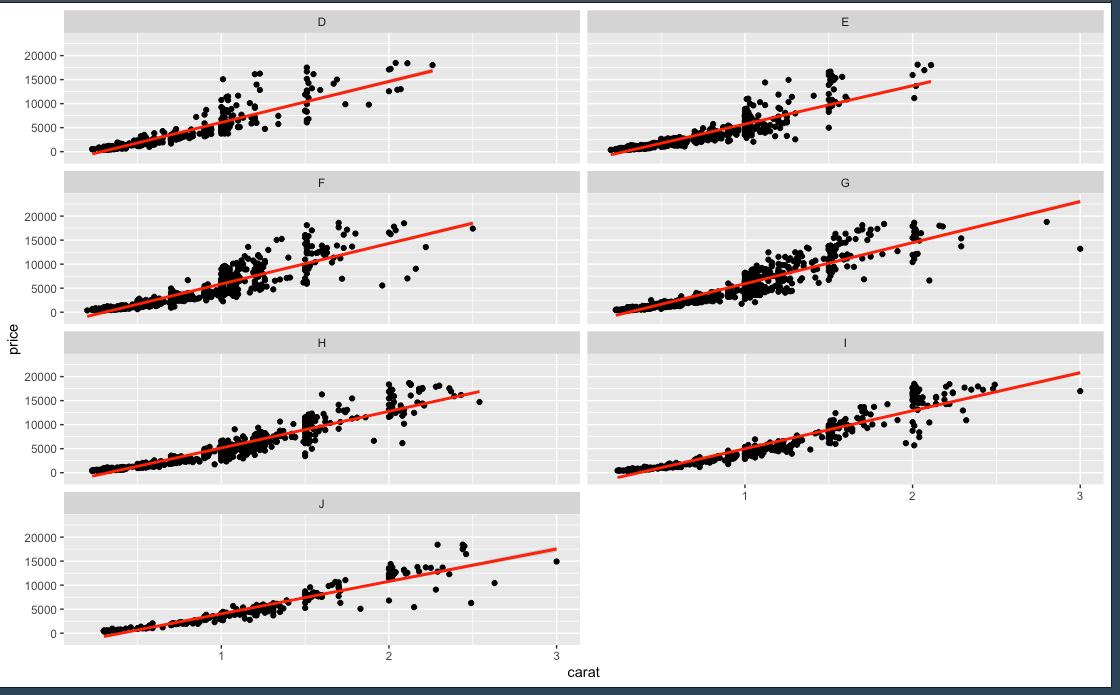
small_diamonds <- sample_n(diamonds, 5000)
ggplot(small_diamonds, mapping = aes(carat, price)) + geom_point() + geom_smooth(method = "lm", col="red") + facet_wrap(~color, ncol=2)
เราสามารถ เปลี่ยนสีพื้นหลังได้ เพราะสีพื้นหลังของ ggplot มันไม่ได้ช่วยให้การเล่าเรื่องของเราดีขึ้น เราจะทำให้มันสะอาดตาและทำให้กราฟของเราเด่นขึ้นมาด้วย และ ใส่ชื่อเพิ่มข้อมูลให้เห็นรายละเอียดมากขึ้น
small_diamonds <- sample_n(diamonds, 5000)
ggplot(small_diamonds, mapping = aes(carat, price)) + geom_point() + geom_smooth(method = "lm", col="red") + facet_wrap(~color, ncol=2) + theme_minimal() + labs(title = "Ralationship between carat and price by color", x = "Carat", y = "Price USD", caption = "Source: Diamonds from ggplot2 package")
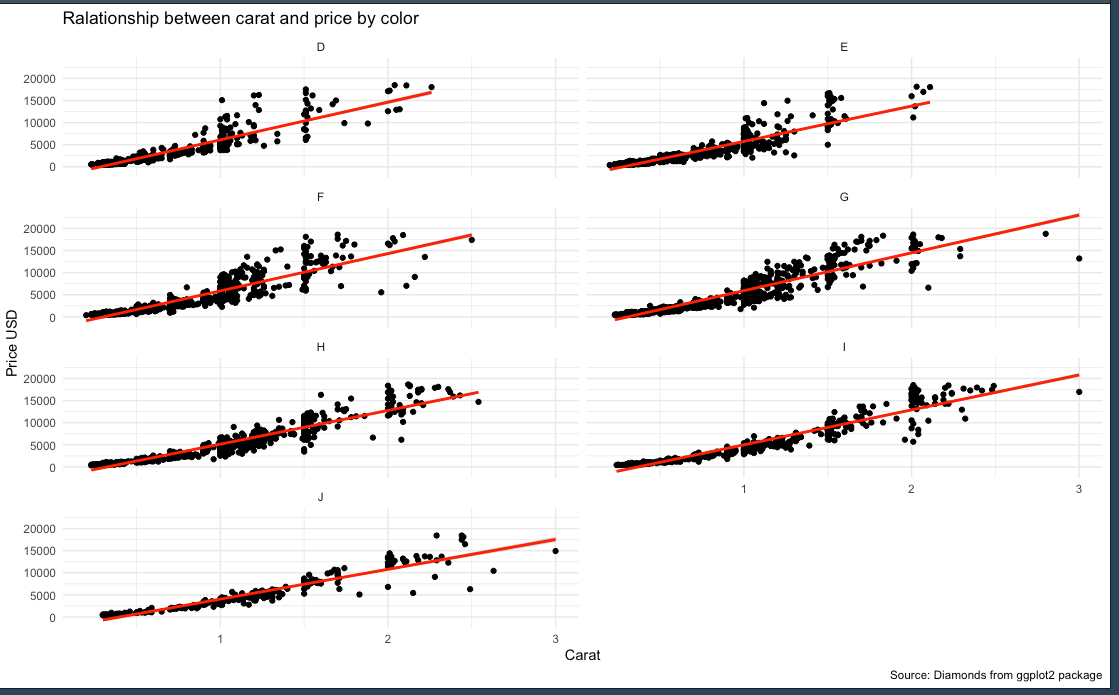
เราลองมาสรุปผล กราฟนี้สักนิดนึง
สรุปได้ว่า : ยิ่งขนาดของ carat สูงขึ้น price ก็สูงขึ้น ไม่ว่าจะเป็นสีไหน ก็เป็นแบบเดียวกัน
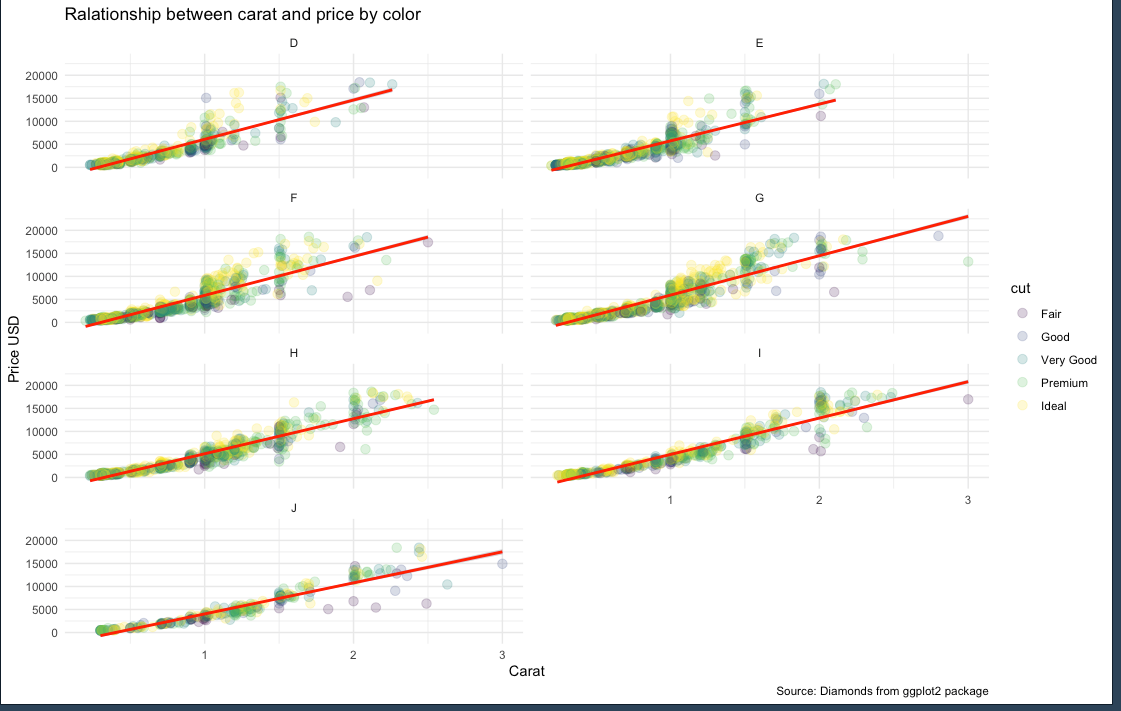
ตัวอย่างสุดท้าย อยากจะ mapping color ลงไปให้ดูง่ายขึ้น
สามารถใส่สีเข้าไปในแต่ด้วย column cut
small_diamonds <- sample_n(diamonds, 5000)
ggplot(small_diamonds, mapping = aes(carat, price, col=cut)) + geom_point(size=3, alpha =0.2) + geom_smooth(method = "lm", col="red") + facet_wrap(~color, ncol=2) + theme_minimal() + labs(title = "Ralationship between carat and price by color", x = "Carat", y = "Price USD", caption = "Source: Diamonds from ggplot2 package")
คอร์สนี้ดีมากกกก (ไก่ ล้านตัว) ใครอ่านจบ แนะนำว่าให้ไปสมัครเรียน ติดตามได้ที่ link ด้านล่างนี้เลย
Course Online DATA ROCKIE Bootcamp