บันทึกการอ่านหนังสือ Hands On Programming with R Book สำหรับนักวิทยาศาสตร์ข้อมูล Data Science - sprint 03

บทความนี้เป็นบันทึกและสรุปหนังสือ Hands On Programming with R ตั้งแต่บทที่ 1 - 6 โดยคัดเฉพาะส่วนที่สำคัญและไม่ซ้ำกับบทความที่ผ่านๆมา ซึ่งจะช่วยให้คุณเข้าใจการเขียนโปรแกรมด้วยภาษา R มากยิ่งขึ้น
Weighted Dice
ความพิวเตอร์จะช่วยจัดการชุดข้อมูลและแสดงผล ซึ่ง นักวิทยาศาสตร์ข้อมูลจะเป็นคนที่รู้วิธีการสร้างโปรแกรมและมีความสามารถที่จะปรับปรุงกระบวนการเกี่ยวกับข้อมูลในเรื่องต่างๆ ดังนี้
- การจัดเก็บข้อมูล
- การเรียกค่าของข้อมูลที่จัดเก็บเอาไว้
- การคำนวนที่ซับซ้อนกับข้อมูลจำนวนมาก
- การทำงานซ้ำๆ
คอมพิวเตอร์จะช่วยให้ทำงานเหล่านี้ได้อย่างรวดเร็วและไม่เกิดข้อผิดพลาด และช่วยตัดสินใจและการตีความข้อมูล
สมมติว่าอยากจะไป las vegas เพื่อจะไปคว้าเงินก้อนโต ส่วนใหญ่คิดว่าเป็นเรื่องหมูๆสำหรับนักสถิติแน่ๆ แต่ว่าอันที่จริงแล้วแม้แต่นักสถิติเองก็เสียเงิน เพราะว่าแต่ละเกมในคาสิโนถึงจะแพ้ มันก็ยังอยากจะเล่นต่อไป
โดยที่ R ช่วยให้คุณวิเคราะห์สิ่งเหล่านั้นได้ ก่อนที่จะไปเล่นการพนัน คุณสามารถจะสร้างการสุ่มตัวเลขด้วยภาษา R ได้
component ใน ภาษา R ประกอบไปด้วย Object, Data Type, Classes, Notation, Function, Evironment , if tree (if else), loop, vectorization ทั้งงหมดนี้เป็นพื้นฐานของภาษา R
ในบทต่อไปนี้ คุณจะได้เรียน
- การใช้ R ใน Rstudio
- การ Run คำสั่ง R
- การสร้าง R Object
- การเขียน R function
- การ Load R package
- การสร้าง random
- การ plot อย่างง่าย
- ฟังก์ชัน help เมื่อคุณต้องการมัน
The R User Interface
ภาพรวมของภาษา R เขียนแบบสรุปสั้นๆ สำหรับ คนที่มีความรู้เรื่องเขียนโปรแกรมอยู่แล้วซึ่งไม่ได้ยาก ในบทนี้เขาพยายามจะแนะนำข้อดีของการบันทึกข้อมูลบนคอมพิวเตอร์ เพราะเราสามารถที่จะบันทึกข้อมูลต่างๆที่เราสนใจเอาไว้ได้โดยไม่ต้องจำ
แล้วข้อมูลไหนควรจะบันทึก? เป็นคำถามที่คล้ายที่เรากำลังเขียนการจดโน๊ต Notion นี้แหละ ว่าสิ่งไหนสำคัญก็ให้เราทำการบันทึกเอาไว้
มาถึงสิ่งที่เราจะต้องรู้ว่าจะทำอย่างไร ให้สามารถบันทึกข้อมูลลงคอมพิวเตอร์ได้ ซึ่งก็มีโปรแกรม RStudio นี้แหละที่จะมาช่วยเรา
ในส่วนถัดไปนี้จะเป็นการบันทึกเฉพาะ syntax ของ Rstudio ในบางเรื่องเท่านั้น เช่น
[1] โดยปกติผลลัพท์จะถูกนำด้วย [1] ซึ่งเป็นตัวบอกเราว่านี้คือบรรทัดเริ่มต้นของผลลัพท์ที่คำนวนมา เพราะในบรรทัดไปจะเป็นตัวเลขอื่น อาจจะเป็น [13] ก็ได้ เลข 13 คือ ลำดับของข้อมูลใน ชุดข้อมูลของคำตอบ
100:300 ในภาษา R สามารถสร้าง sequence ของตัวเลขได้โดยใช้เครื่องหมาย Colon คั่นเอาไว้
100:130
## [1] 100 101 102 103 104 105 106 107 108 109 110 111 112
## [14] 113 114 115 116 117 118 119 120 121 122 123 124 125
## [27] 126 127 128 129 130
ในภาษา R หากว่าเราพิมพ์คำสั่งไป แต่ว่าเราไม่สั่ง run มันก็ยังไม่ทำงาน มันจะทำงานก็ต่อเมื่อเราก็ Ctrl + Enter ซึ่งในภาษา R มันจะนับบรรทัดที่เริ่มต้นด้วยตัวเลข แล้ว จบด้วยตัวเลข ถ้าในแต่ละบรรทัดมีเครื่องหมาย Operator คั่นอยู่ เช่น
5 -
+
+
+1
## 4
ถ้าพิมพ์ผิด R จะส่งค่า Error ทันที
3 % 5
## Error: unexpected input in "3 % 5"
Object
: Operator เป็นการสร้าง Vector แบบ 1 มิติ ของชุดตัวเลข เช่น
1:6
## 1 2 3 4 5 6
โดยที่พิมพ์ชุดตัวเลขออกมาอย่าง code ด้านบน มันไม่สามารถที่จะนำมาประยุกต์ใช้ต่อได้ มันจะต้องเก็บข้อมูลเอาไว้ใน memory สักที่ก่อน อย่างที่เราเข้าใจกันอยู่แล้ว นั่นก็คือ object ถ้าเราต้องการใช้ตัวเลขหรือชุดข้อมูลนั่นอีกครั้ง เราก็เรียกชื่อ Object อาจจะตั้งชื่อว่า a หรือ b ก็ได้ เช่น
a <- 1
a
## 1
a + 2
a
## 3
a
## 1
เครื่องหมาย <- (arrow) เป็นเครื่องหมายเทียบเครื่องหมาย = (เท่ากับ) สามารถใช้แทนกันได้ มันเป็นเครื่องหมายในการสร้าง Object เพื่อเก็บข้อมูล
คราวนี้มาลองเก็บข้อมูล 1 ถึง 6 กันบ้าง
die <- 1:6
die
# 1 2 3 4 5 6
ในการตั้งชื่อ Object มีกฏในการตั้ง 2 อย่าง คือ
- ไม่สามารถขึ้นต้นด้วยตัวเลข
- ไม่สามารถใช้อักขระพิเศษได้
ข้อควรจำ
R เป็น case-sensitive ตัวเล็กตัวใหญ่จะเป็นคนละตัวแปรกัน
ภาษา R จะเขียนทับข้อมูลลงในตัวแปรทันที
คราวนี้เราก็จะสามารถเข้าถึงข้อมูลได้แล้ว ถ้าเราพิมพ์ข้อมูลด้วยคำว่า die
แล้วทำอะไรกับ die ได้บ้าง?
เราสามารถคำนวนข้อมูลด้วย operator ต่างๆได้ เช่น
die - 1
## 0 1 2 3 4 5
die / 2
## 0.5 1.0 1.5 2.0 2.5 3.0
die * die
## 1 4 9 16 25 36
R จะใช้ element - wish ในการจัดการข้อมูล โดยที่ภาษา R จะทำ Operator ลงไปในทุกๆ element ในชุดข้อมูล เช่นเมื่อ run คำสั่ง die - 1 มันจะทำการลบข้อมูลแต่ละตัวด้วย 1 ทุกตัว
ถ้าสมมติว่า มี vector 2 ชุดที่ไม่เท่ากัน ในภาษา R มันจะนำส่วนที่สั้นที่สุดมาทำการ Operator ซ้ำๆกับทุกตัว เช่น
1:2
## 1 2
1:4
## 1 2 3 4
die
## 1 2 3 4 5 6
die + 1:2
## 2 4 4 5 6 8
## 1 + 1 = 2
## 2 + 2 = 4
## 3 + 1 = 4
## 4 + 2 = 6
## 5 + 1 = 6
## 6 + 2 = 8
Functions
ฟังก์ชันในภาษา R ก็จะคล้ายๆกับภาษาอื่นๆทั่วไป โดยจะมีฟังก์ชันมาให้ใช้งาน อย่างเช่น SUM() MEAN() เป็นต้น โดยการผ่านข้อมูลเข้าไปใน function ที่เราเรียกว่า arguments
round(3.1415)
## 3
factorial(3)
## 6
R สามารถที่ผ่านฟังก์ชัน เข้าไปใน ฟังก์ชันได้ เป็นฟังก์ชันที่ซ้อนกัน โดยการทำงานของมันจะทำงานฟังก์ชันด้านในสุดก่อนเสมอ เช่น
mean(1:6)
## 3.5
mean(die)
## 3.5
round(mean(die))
## 4
นอกจากจะผ่านข้อมูลเข้าไปในฟังก์ชันด้วยค่าเพียงค่าเดียวก็ยังสามารถที่จะผ่านข้อมูลเข้าไปได้หลายตัวเช่นเดียวกัน โดยการแยก Arguments ด้วย comma
sample(x = die, size = 1)
## 2
sample(x = die, size = 1)
## 1
sample(x = die, size = 1)
## 6
เพื่อป้องกันการผิดพลาดแนะนำให้เขียนชื่อของ arguments ให้ถูกต้อง แต่ถ้าเขียนขื่อผิดก็ไม่ต้องกังวลไป เพราะมันจะเตือนว่าใส่ค่าผิด
round(3.1415, corners = 2)
## Error in round(3.1415, corners = 2) : unused argument(s) (corners = 2)
แต่ถ้าไม่แน่ใจว่าชื่อที่ถูกต้องคืออะไร ให้ลองใช้ฟังก์ชัน args(function name)
มันจะเป็นเหมือน help สำหรับ arguments ของฟังก์ชันที่เราต้องการค้นหา
args(round)
## function (x, digits = 0)
## NULL
ข้อแนะนำเมื่อมีการเขียนฟังก์ชันที่การใส่ arguments หลายๆตัว ให้ระบุชื่อเสมอเพื่อป้องกันข้อผิดพลาด เพราะมันจะช่วยให้คุณหรือเพื่อนๆของคุณเข้าใจ code ของคุณ ชัดเจน และ อ้างอิง input ได้อย่างถูกต้อง
Writing Your Own Function
มาสร้าง function ของตัวเองโดยที่บางฟังก์ชันก็ไม่จำเป็นต้องสร้างขึ้นใหม่ เราเพียงแค่ใส่ฟังก์ชันที่มีอยู่มาวางไว้ใน block function ของเราหรือจะเรียกว่า wrapped ก็ได้ สมมติว่าเราจะต่อยอดจากฟังก์ชันที่มีอยู่แล้วในหัวข้อที่แล้ว โดยตั้งชื่อว่า roll โดยใช้ ฟังก์ชัน roll นี้เป็นฟังก์ชันทอยลูกเต๋า ซึ่งในแต่ละครั้งที่เรียกใช้ฟังก์ชัน roll ก็จะคืนค่ากลับมา เช่น
roll()
## 8
roll()
## 3
roll()
## 7
ในการสร้างฟังก์ชันมีพื้นฐาน 3 อย่างที่สำคัญ คือ a name, a body of code, and a set of arguments
โดยเวลาสร้าง function จะมีรูปแบบโครงสร้างแบบนี้
my_function <-function() {}
roll <-function() {
die <- 1:6
dice <-sample(die, size = 2, replace = TRUE)
sum(dice)
}
roll()
## 9
สังเกตว่า บรรทัดสุดท้าย sum(dice) บรรทัดนี้ โดยปกติแล้วจะมีคำว่า return เพื่อคืนค่าของฟังก์ชันแต่ภาษา R ไม่จำเป็นต้องระบุ แต่จะเห็นว่า sum(dice) จะไม่ tab เท่ากับบรรทัดอื่นๆ เป็นตัวบอกว่าจะ return ค่า
Arguments
สมมติว่าเราลบบรรทัด die ออก แล้วเปลี่ยน die เป็น bones จะเกิดอะไรขึ้น
roll2 <-function() {
dice <-sample(bones, size = 2, replace = TRUE)
sum(dice)
}
แน่นอนว่ามันจะเกิด error เพราะว่ามันไม่มี ตัวแปร bones อยู่ใน function
roll2()
## Error in sample(bones, size = 2, replace = TRUE) :
## object 'bones' not found
วิธีแก้เราก็แค่ใส่ค่า arguments ลงไปใน function
roll2 <-function(bones) {
dice <-sample(bones, size = 2, replace = TRUE)
sum(dice)
}
วิธีที่จะช่วยป้องกันการ error อีกอย่างหนึ่งก็คือ ควรจะตั้งค่า default เอาไว้ด้วย
roll2 <-function(bones = 1:6) {
dice <-sample(bones, size = 2, replace = TRUE)
sum(dice)
}
Package and Help Pages - 03
คราวนี้เราก็มาถึงการที่จะทำอย่างไรให้การ simulates นั้นง่ายขึ้น
เครื่องมือที่จะช่วยพวกเรานั้น มีอยู่ 2 อย่าง คือ repetition และ virsualization
เราจะทำการทอยลูกเต๋าโดยการเรียกฟังก์ชันที่ชื่อว่า replicate และจะแสดงผลการทอยลูกเต๋าโดยเรียกใช้ฟังก์ชันชื่อ qplot
อันที่จริงแล้ว qplot ไม่ได้เป็น package ที่ติดมากับโปรแกรม R เราจะต้องมาติดตั้งเสริมเพิ่มเติม
packages
ไม่ว่าใครๆก็เขียนโปรแกรมด้วยภาษา R ที่ออกแบบเครื่องมือเพื่อช่วยให้หลายๆคนวิเคราะห์ข้อมูลได้อย่างสะดวก พวกเขาจึงสร้างเครื่องมือแบ่งปันให้ใครก็ได้ใช้งานมัน
ggplot2 packages
วิธีการติดตั้ง package เสริม
- เปิด RStudio
- สั่ง Run command บน console
install.packages("ggplot2") - รอจนติดตั้งเสร็จ ง่ายจนงง!
library
ลองทดสอบดูว่าสามารถเรียกฟังก์ชัน qplot ได้หรือไม่
qplot
## Error: object 'qplot' not found
ถ้าไม่ได้ให้ใช้ฟังก์ชันติดตั้ง library(”ggplot2”) เพื่อเป็นการเรียก package ที่ติดตั้งมาใช้งาน
qplot
## (quite a bit of code)
มาลองทดสอบ qplot ฟังก์ชันโดย run ข้อมูล x กับ y แล้ว plot กราฟด้วย qplot
x <-c(-1, -0.8, -0.6, -0.4, -0.2, 0, 0.2, 0.4, 0.6, 0.8, 1)
x
## -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0
y <- x^3
y
## -1.000 -0.512 -0.216 -0.064 -0.008 0.000 0.008
## 0.064 0.216 0.512 1.000
qplot(x, y)
ในการแสดงผลหรือการทำ visualization จะใช้ Scatterplots สำหรับหาความสัมพันธ์ระหว่าง 2 ตัวแปร แต่ส่วนกรณีที่เป็นตัวแปรเดียวเราจะใช้ histogram ในการหาค่าการกระจายของข้อมูล อย่างเช่น สร้าง vector ขึ้นมา 1 ชุด ใส่ลงไปในตัวแปร x แล้ว plot ด้วย qplot โดยให้ binwidth เท่ากับ 1
binwidth คือ ระยะห่างของแต่ละแท่งใน histogram
x <-c(1, 2, 2, 2, 3, 3)
qplot(x, binwidth = 1)
ถ้าได้ลองทำการ plot ค่าดูแล้วจะเห็นว่า ค่า interval ของ [1,2) จะมีความสูงเท่ากับ 1
เครื่องหมายปีกกา [ หมายถึงค่าเริ่มต้น ส่วน เครื่องหมายปีกกา ) คือ สิ้นสุดของ range ที่พูดถึง
x2 <-c(1, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 4)
qplot(x2, binwidth = 1)
เวลาที่ถ้า generate ออกมาแล้วความน่าจะเป็นของค่าที่เกิดขึ้นจำนวนมาก ความถี่ก็จะสูง ซึ่งอาจจะออกมาอยู่ในรูปของ พีระมิด ด้านเท่า
roll2 <-function(bones) {
dice <-sample(bones, size = 2, replace = TRUE)
print(dice)
sum(dice)
}
สมมติว่าคุณ ทอยลูกเต๋า หลายครั้งและบันทึกผลลัพท์เอาไว้ คุณจะคาดหวังว่าจะมีค่าใดสักค่าหนึ่งที่ออกบ่อยมากกว่าค่าอื่นๆ ซึ่ง ถ้าลอง plot ด้วย qplot ก็จะเห็นว่ามันเป็นแบบนั้นโดยที่ histogram จะแสดงให้เห็นผลรวมของฟังกชัน roll ที่เขียนเอาไว้หัวข้อที่ผ่านมา ว่าปรากฎบ่อยครั้งแค่ไหน ถ้าทอยลูกเต๋าแบบเท่าๆกัน โดยใช้ฟังก์ชัน replicate ตาม code ที่แสดงด้านล่าง
replicate(3, 1 + 1)
## 2 2 2
replicate(10,roll())
## 3 7 5 3 6 2 3 8 11 7
replicate(10, roll2(1:6))
##[1] 2 2
##[1] 3 4
##[1] 1 6
##[1] 5 5
##[1] 3 1
##[1] 4 5
##[1] 1 4
##[1] 4 3
##[1] 2 2
##[1] 1 4
##[1] 4 7 7 10 4 9 5 7 4 5
โปรดจำเอาไว้ว่า ฟังก์ชันนี้ก็เหมือนการทอยลูกเต๋าโดยใช้ลูกเต๋าจริงๆที่มีประสิทธิภาพ โดย pattern ความถี่จะเกิดขึ้นก็ต่อเมื่อมีการทอยเต๋าจำนวนมาก เช่น 10000 ครั้ง เราสามารถ simulation ได้ง่ายๆโดยใช้ฟังก์ชัน roll และ replicate
rolls <-replicate(10000,roll())
qplot(rolls, binwidth = 1)
ถ้าได้ลอง run code ด้านบนแล้วก็จะเห็นพีระมิด ด้านเท่าเกิดขึ้น โดยค่าผลรวมที่เกิดขึ้นบ่อยที่สุดก็คือ 7 เพราะว่า ความน่าจะเป็นของ sample space เลข 7 มีค่าสูงที่สุด มากกว่าเลขอื่นๆ อย่าง การออก [6,6]
Getting Help with Help Pages
Help Page ของ RStudio มีประโยชน์มาก เพราะว่าฟังก์ชันที่ติดมากับ R มีมากกว่า 1000 ฟังก์ชัน ซึ่งสามารถอ่านคู่มือของมันได้ง่ายๆเพียงแค่พิมพ์ชื่อฟังก์ชันที่เราเจอมา
สมมติว่าเราไม่เคยรู้จักฟังก์ชันชื่อ sample เลย ลองค้นหาดูด้วย help(sample)
sample(x, size, replace = FALSE, prob = NULL)
เราก็จะเห็น help page เด้งขึ้นมาให้เราอ่านศึกษาเหมือนเป็นคู่มือ
เราเห็น arguments ที่ชื่อ prob มันก็คือ probability ที่เราอยากเปลี่ยนแปลงความน่าจะเป็นของชุดข้อมูล ยกตัวอย่างเช่น
roll <-function() {
die <- 1:6
dice <-sample(die, size = 2, replace = TRUE,
prob =c(1/8, 1/8, 1/8, 1/8, 1/8, 3/8))
sum(dice)
}
จากปกติถ้าเราไม่ใส่ค่า prob มันจะมี 7 ที่มีความถี่สูงกว่าเลขอื่นๆ แต่เมื่อ run code ด้านบนจะพบว่า เลข 6 ที่ความน่าจะเป็นน้อย จะมีค่าความถี่ที่สูงขึ้นเพราะเราปรับความน่าจะเป็นของ ลูกเต๋าหน้า 6 แต้มเป็น 3/8 หรือ 37.5 % นั่นเอง
Playing Cards - 04
ในบทนี้ จะมาเรียนรู้ภาษา R ด้วยการสร้างเกมไพ่ขึ้นมา โดยจะมาดูวิธีการ เก็บ ดึง และ เปลี่ยนข้อมูลใน memory โดยใช้ทักษะการจัดการข้อมูล
เราจะได้เรียนอะไรจากในบทนี้
- การบันทึก data type เช่น string และ logical
- การบันทึก vector matrix array list และ data frame
- การ load และ save ชุดข้อมูล หรือ data set ด้วย R
- การ Extract data set
- การ Change data set
- การเขียนทดสอบ
- ใช้สัญลักษณ์ NA แทน missing - value
Task 1 : มาเรียนการออกแบบและสร้างเกมไพ่
Task 2 : เขียน function deal และ shuffle และ การ extract values
Task 3 : การแก้ไขข้อมูล
R Object - 05
ในหัวข้อนี้เราจะมาสร้างไพ่ 52 ใบด้วยภาษา R กัน โดย R Object เป็นเหมือนตัวแทน สำรับไพ่ ก็คล้ายๆกับทำตารางใน Excel นั่นล่ะ พอทำเสร็จแล้วหน้าตาก็จะคล้ายๆตารางด้านล่างนี้
face suit value
king spades 13
queen spades 12
jack spades 11
ten spades 10
nine spades 9
eight spades 8
...
เราจะต้องทำข้อมูลของชุดไพ่เองทั้งหมดมั้ย บอกได้ว่า ไม่จำเป็นเพราะว่า เราสามารถ load ข้อมูล data set ของ R ได้
Vector
เริ่มด้วย Object ประเภทแรก นั่นก็คือ Vector เป็นชุดข้อมูลแบบ 1 มิติ และเก็บข้อมูลได้เพียงแค่ 1 ชนิดเท่านั้น ได้แก่ doubles, integers, characters, logicals, complex, and raw เช่น ถ้าข้อมูลใน vector เป็น characters ก็จะต้องเป็น characters เท่านั้น และแต่ละ vector เราสามารถสร้างชุดข้อมูลมาได้ด้วย ฟังก์ชัน c
die <-c(1, 2, 3, 4, 5, 6)
die
## 1 2 3 4 5 6
is.vector(die)
## TRUE
เก็บข้อมูลได้ชนิดเดียวแต่ละ vector
int <-c(1L, 5L)
text <-c("ace", "hearts")
sum(int)
## 6
sum(text)
## Error in sum(text) : invalid 'type' (character) of argument
สามารถเช็ค ตัวแปรได้ว่าเป็น vector หรือไม่ด้วย is.vector(object)
เราสามารถเช็คความยาวของข้อมูลในตัวแปรได้ โดยใช้ ฟังก์ชัน length
five <- 5
five
## 5
is.vector(five)
## TRUE
length(five)
## 1
length(die)
## 6
Doubles
double เป็นข้อมูชนิดตัวเลข สามารถเก็บข้อมูลจำนวนเต็ม จำนวนบวก จำนวนลบ ใหญ่หรือเล็กก็ได้ จะเป็น decimal หรือไม่ก็ได้
die <-c(1, 2, 3, 4, 5, 6)
die
## 1 2 3 4 5 6
typeof(die)
## "double"
Integers
integer เป็นข้อมูลชนิดตัวเลข เช่นเดียวกันแต่เราไม่ค่อยได้ใช้เพราะใช้ double เป็นส่วนใหญ โดยตัวเลขจะต้องตามด้วย L ซึ่ง การกำหนดข้อมูลเป็น integer ใน memory จะแม่นยำกว่าแบบ double เช่น
int <-c(-1L, 2L, 4L)
int
## -1 2 4
typeof(int)
## "integer"
Characters
character vector เป็นชุดข้อมูล string เหมือน code ด้านล่างนี้
text <-c("Hello", "World")
text
## "Hello" "World"
typeof(text)
## "character"
typeof("Hello")
## "character"
Logicals
เป็นชนิดข้อมูลตรรกะ ที่เก็บ vector TRUE หรือ False
logic <-c(TRUE, FALSE, TRUE)
logic
## TRUE FALSE TRUE
typeof(logic)
## "logical"
typeof(F)
## "logical"
Complex And Raw
Complax
เป็นข้อมูลพิเศษที่สร้างขึ้นเพื่อรองรับข้อมูลใช้วิเคราะห์ข้อมูลเชิงซ้อน
comp <-c(1 + 1i, 1 + 2i, 1 + 3i)
comp
## 1+1i 1+2i 1+3i
typeof(comp)
## "complex"
Raw
เป็นชนิดข้อมูลที่เก็บ binary เป็น byte
raw(3)
## 00 00 00
typeof(raw(3))
## "raw"
Attribute
แอททริบิวด์ เป็นข้อมูลชนิดหนึ่งที่อยู่ใน vector แต่มันจะไม่แสดงข้อมูลออกมาให้เห็นจะต้องเรียกดูด้วยฟังก์ชันพิเศษ เช่น attributes() มันจะคล้ายๆ กับ metadata ถ้าไม่มี attribute มันจะแสดงค่า NULL ออกมา
NULL ใช้แทนค่าว่าง ของ object
Names Attribute
names เป็น attributes ฟังก์ชันของ vector ที่จะช่วยสร้าง tag name คล้ายกับ header ของตาราง เช่น
เริ่มต้นที่ เรามี object ที่ชื่อ die แล้วเรียก names attribute เราจะได้ NULL เพราะว่ายังไม่มีค่าอะไรใน names()
names(die)
## NULL
เดิมตัวแปร die จะมี ค่า vector 1, 2, 3, 4, 5, 6 อยู่แล้วในตัวแป
die <- c(1,2,3,4,5,6)
จากนั้นเราก็ใส่ attribute ที่มี object vector เข้าไปในตัวแปร die
names(die) <-c("one", "two", "three", "four", "five", "six")
คราวนี้เราเรียก names attributes
names(die)
## "one" "two" "three" "four" "five" "six"
attributes(die)
## $names
## [1] "one" "two" "three" "four" "five" "six"
เมื่อเราเรียก object die เราจะได้
die
## one two three four five six
## 1 2 3 4 5 6
เรายังสามารถ operation กับตัวแปร die ได้โดยที่ attribute name ไม่เปลี่ยนแปลง เช่น
die + 1
## one two three four five six
## 2 3 4 5 6 7
แต่ถ้าอยากเปลี่ยนแปลง header หรือ names attribute เราก็แค่ใส่ object vector เข้าไปใน names(object) ใหม่อีกครั้ง เช่น
names(die) <-c("uno", "dos", "tres", "quatro", "cinco", "seis")
die
## uno dos tres quatro cinco seis
## 1 2 3 4 5 6
หากเราต้องการลบ names attributes ทิ้งก็ใส่ NULL เข้าไป
names(die) <- NULL
die
## 1 2 3 4 5 6
Dim Attribute
dim หรือ dimension เป็น attribute ที่เอาไว้แปลงข้อมูล vector ให้เป็น array อย่างเช่น
สร้าง array 2 มิต 2 แถว 3 คอลัมน
dim(die) <-c(2, 3)
die
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6
3 แถว 2 คอลัมน์
dim(die) <-c(3, 2)
die
## [,1] [,2]
## [1,] 1 4
## [2,] 2 5
## [3,] 3 6
หรือจะสร้างเป็น 3 มิติก็ได้
dim(die) <-c(1, 2, 3)
die
## , , 1
##
## [,1] [,2]
## [1,] 1 2
##
## , , 2
##
## [,1] [,2]
## [1,] 3 4
##
## , , 3
##
## [,1] [,2]
## [1,] 5 6
Matrices
เมื่อหัวข้อที่แล้วเรารู้จักกับ attribute dim ในการสร้าง array หลายมิติ อย่าง 2 มิติ เราสร้าง vector แล้วกำหนด row และ column แต่เราสามารถใช้ metrix function ในการสร้าง array 2 มิติได้เลยเช่นกัน
m <-matrix(die, nrow = 2)
m
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6
ถ้าอยากสลับตำแหน่งของลำดับข้อมูลให้เรียงตามแถวก็ใส่ arguments byrow เข้าไป
m <-matrix(die, nrow = 2, byrow = TRUE)
m
## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
Array
Array เป็น function ไว้สำหรับสร้าง array หลายมิติ n - dimension แต่จะไม่สามารถปรับแต่งได้เหมือนกับ matrix function ในการสร้าง array หลายมิติ จะต้องสร้าง vector ขึ้นมา 2 ชุด คือ vector และ dim
ar <-array(c(11:14, 21:24, 31:34), dim =c(2, 2, 3))
ar
## , , 1
##
## [,1] [,2]
## [1,] 11 13
## [2,] 12 14
##
## , , 2
##
## [,1] [,2]
## [1,] 21 23
## [2,] 22 24
##
## , , 3
##
## [,1] [,2]
## [1,] 31 33
## [2,] 32 34
Class Attribute
เวลาที่สร้าง ชุดข้อมูลขึ้นมามันจะสร้าง class attribute ขึ้นมาเสมอ แล้ว class attribute มีไว้ทำอะไร
ก็เพื่อที่จะดูการเปลี่ยนแปลงของข้อมูลว่าถูกเปลี่ยนไปชนิดไหน และเพื่อที่จะจัดการข้อมูลนั้นๆได้
dim(die) <-c(2, 3)
typeof(die)
## "double"
class(die)
## "matrix"
class("Hello")
## "character"
class(5)
## "numeric"
Date Time
date time เป็น data type ชนิด double และเป็น class POSIXct และ POSIXt มี 2 class โดย ส่วนใหญ่จะใช้ POSIXct เป็น framework แทน วันที่และเวลา ซึ่ง POSIXct แต่ละค่าจะแทนด้วย ตัวเลขวินาที และ วันเดือนปีตาม format UTC หรือ Universal Time Coordinated zone
now <-Sys.time()
now
## "2014-03-17 12:00:00 UTC"
typeof(now)
## "double"
class(now)
## "POSIXct" "POSIXt"
เราสามารถเปลี่ยนเป็นวินาทีได้โดยใช้ฟังก์ชัน unclass(now)
unclass(now)
## 1395057600
Factors
ฟังก์ชัน Factor เป็นฟังก์ชันที่ทำหน้าที่ จัดกลุ่มข้อมูล หรือหมวดหมู่ อย่างเช่น เพศ หรือ ชุดสี เป็นต้น ซึ่ง เราสามารถสร้าง ชุดข้อมูล vector ขึ้นมา 1 ชุดแล้วใส่เข้าไปใน factors นำมาเก็บเอาไว้ในตัวแปร แล้วต้องนำไปใส่ในฟังก์ชัน attribute เพื่อเพิ่ม metadata level ให้กับ object
gender <-factor(c("male", "female", "female", "male"))
typeof(gender)
## "integer"
attributes(gender)
## $levels
## [1] "female" "male"
##
## $class
## [1] "factor"
สังเกตจาก code ด้านบนแล้วเราจะเห็นว่า gender จะมีชนิดของข้อมูลเป็น integer เพราะว่า ส่วนใหญ่จะนำ factor มาใช้กับข้อมูลเชิงสถิติ เพราะว่าจะต้องแทน string ด้วย ตัวเลข
unclass(gender)
## [1] 2 1 1 2
## attr(,"levels")
## [1] "female" "male"
Lists
ลิสท์ คล้ายกับ Vector แต่ vector จะเก็บข้อมูลได้เพียงแค่ ชนิดใดชนิดหนึ่งเท่านั้น แต่ List จะสามารถเก็บค่าได้ชนิดของข้อมูลได้หลายแบบ
list1 <-list(100:130, "R",list(TRUE, FALSE))
list1
## [[1]]
## [1] 100 101 102 103 104 105 106 107 108 109 110 111 112
## [14] 113 114 115 116 117 118 119 120 121 122 123 124 125
## [27] 126 127 128 129 130
##
## [[2]]
## [1] "R"
##
## [[3]]
## [[3]][[1]]
## [1] TRUE
##
## [[3]][[2]]
## [1] FALSE
Data frame
Data frame เป็น list ที่มี 2 มิติ ซึ่งมีประโยชน์มากในการใช้เป็นโครงสร้างสำหรับวิเคราะห์ข้อมูล เทียบได้กับ excel spreadsheet เอาไว้เก็บข้อมูลที่มี format ใกล้เคียงกัน
Data frame เป็นกลุ่มข้อมูล vector แบบตาราง 2 มิติ ซึ่ง data frame สามารถที่จะใส่ข้อมูลที่แตกต่างกันได้ไม่เหมือนกับ data type ประเภทอื่นๆ แต่ว่า ในแต่ละ column จะต้องเป็นข้อมูลชนิดเดียวกันไปทั้ง column
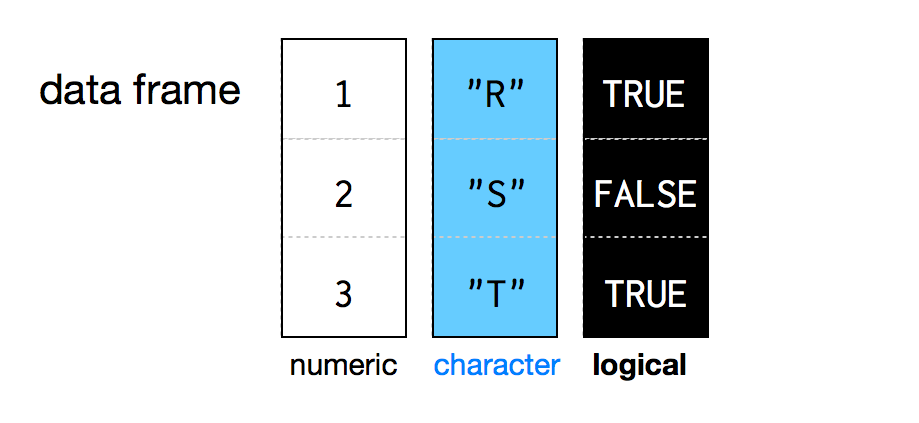
เราจะใช้ data.frame เป็นตัวสร้าง data frame ขึ้นมาก โดยในแต่ละ vector ควรจะสร้าง ชุดข้อมูลลงใน vector ให้เท่ากัน
df <-data.frame(face =c("ace", "two", "six"),
suit =c("clubs", "clubs", "clubs"), value =c(1, 2, 3))
df
## face suit value
## ace clubs 1
## two clubs 2
## six clubs 3
ถ้าลองเช็ค ชนิดของ data frame ก็จะเห็นว่ามันคือ list
typeof(df)
## "list"
class(df)
## "data.frame"
str(df)
## 'data.frame': 3 obs. of 3 variables:
## $ face : Factor w/ 3 levels "ace","six","two": 1 3 2
## $ suit : Factor w/ 1 level "clubs": 1 1 1
## $ value: num 1 2 3
เราได้เรียนรู้ชนิดของ data type ที่ใช้ใน R ไปหมดแล้ว เท่านี้เราก็สามารถเริ่มสร้าง เกมไพ่ กันได้แล้ว
deck <-data.frame(
face =c("king", "queen", "jack", "ten", "nine", "eight", "seven", "six",
"five", "four", "three", "two", "ace", "king", "queen", "jack", "ten",
"nine", "eight", "seven", "six", "five", "four", "three", "two", "ace",
"king", "queen", "jack", "ten", "nine", "eight", "seven", "six", "five",
"four", "three", "two", "ace", "king", "queen", "jack", "ten", "nine",
"eight", "seven", "six", "five", "four", "three", "two", "ace"),
suit =c("spades", "spades", "spades", "spades", "spades", "spades",
"spades", "spades", "spades", "spades", "spades", "spades", "spades",
"clubs", "clubs", "clubs", "clubs", "clubs", "clubs", "clubs", "clubs",
"clubs", "clubs", "clubs", "clubs", "clubs", "diamonds", "diamonds",
"diamonds", "diamonds", "diamonds", "diamonds", "diamonds", "diamonds",
"diamonds", "diamonds", "diamonds", "diamonds", "diamonds", "hearts",
"hearts", "hearts", "hearts", "hearts", "hearts", "hearts", "hearts",
"hearts", "hearts", "hearts", "hearts", "hearts"),
value =c(13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 13, 12, 11, 10, 9, 8,
7, 6, 5, 4, 3, 2, 1, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 13, 12, 11,
10, 9, 8, 7, 6, 5, 4, 3, 2, 1)
)
## face suit value
## king spades 13
## queen spades 12
## jack spades 11
## ten spades 10
## nine spades 9
## eight spades 8
## seven spades 7
## six spades 6
## five spades 5
## four spades 4
## three spades 3
## two spades 2
## ace spades 1
## king clubs 13
## queen clubs 12
## jack clubs 11
## ten clubs 10
## ... and so on.
R Notation - 06
จากหัวข้อที่แล้วเรามีสำรับไพ่แล้ว เก็บเอาไว้ในตัวแปร deck เรามีไพ่แล้ว ก่อนจะแจกก็ต้องสลับไพ่กันก่อนแล้วค่อยแจกไพ่ ในการจะสลับไพ่หรือแจกไพ่ได้เราจะมาเรียนรู้ส่ิงที่จำเป็นกันก่อน เช่น การเลือกข้อมูลแต่ละรายการใน deck เป็นต้น
deal(deck)
## face suit value
## king spades 13
6.1 Selecting Values
notation system คือ การบอกตำแหน่งหรืออธิบายลำดับของข้อมูลที่ต้องการ วิธีการเรียกข้อมูลใน data frame จะทำโดยใช้เครื่องหมายปีกกาตามหลังตัวแปร object ที่เก็บข้อมูลเอาไว้ เช่น deck[ i, j] คล้ายกับการแสดงข้อมูลใน array โดยใส่ตำแหน่งเข้าไป ซึ่งะเราจะกั้นตำแหน่ง (index) ด้วย เครื่องหมาย comma
โดยตำแหน่งแรก หรือ (i) คือ row
และตำแหน่งสอง หรือ (j) คือ column
วิธีการป้อน index มีอยู่ 2 วิธี ได้แก่
- Positive integers
- Negative integers
- Zero
- Blank spaces
- Logical values
- Names
6.1.1 Positive Integers
index แบบตัวเลขจำนวนเต็มบวก เช่น deck [1, 1] มันก็จะ return ค่าข้อมูลที่อยู่ใน data frame ออกมาในตำแหน่ง แถวที่ 1 คอลัมน์ที่ 1
deck[1, 1]
## "king"
เราสามารถแทนค่าใน index ด้วย vector ได้ด้วย เช่น
deck[1,c(1, 2, 3)]
## face suit value
## king spades 13
นอกจาก dataframe แล้ว vector ก็ทำได้เช่นเดียวกัน ถ้าอยากใน notation system นี้ เช่น
vec <-c(6, 1, 3, 6, 10, 5)
vec[1:3]
## 6 1 3
แม้ว่าจะเป็น data frame เวลาที่ดึงข้อมูลออกมา ก็สามารถทำให้อยู่ในรูปของ vector ได้เช่นกัน
deck[1:2, 1]
## "king" "queen"
แต่ถ้าอยากให้อยู่ในรูปของ data frame ก็แค่ต้องเพิ่ม drop = False เข้าไปด้วย
deck[1:2, 1, drop = FALSE]
## face
## king
## queen
6.1.2 Negative Integers
index แบบตัวเลขจำนวนเต็มลบ เป็นค่าตรงข้ามกับจำนวนเต็มบวก มันจะ return ค่าทุกตำแหน่งยกเว้น ตำแหน่งที่มันเป็นค่าลบ เช่น
deck[-(2:52), 1:3]
## face suit value
## king spades 13
6.1.3 Zero
ค่าศูนย์ เรารู้ว่ามันไม่ใช่ทั้งค่าจำนวนเต็มบวกและจำนวนเต็มลบ ดังนั้น มันจะไม่คืนค่าอะไรออกมาให้เลย
deck[0, 0]
## data frame with 0 columns and 0 rows
6.1.4 Blank Spaces
blank space จะเป็นตัวบอกว่าเอาทุกตำแหน่ง ถ้าว่างที่ column มันจะดึง column ออกมาทุกแหน่ง เช่น
deck[1, ]
## face suit value
## king spades 13
6.1.5 Logical Values
การใส่ index แบบ Logical มันจะคืนค่ากลับมาให้ เมื่อมันเป็น TRUE เท่านั้น
deck[1,c(TRUE, TRUE, FALSE)]
## face suit
## king spades
rows <-c(TRUE, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F,
F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F,
F, F, F, F, F, F, F, F, F, F, F, F, F, F)
deck[rows, ]
## face suit value
## king spades 13
6.1.6 Names
อยากได้ค่าอะไร ถ้าจำชื่อ column ได้ก็ใส่ชื่อบอกตำแหน่งไปเลย วิธีนี้ช่วยให้เข้าใจง่าย
deck[1,c("face", "suit", "value")]
## face suit value
## king spades 13
# the entire value column
deck[ , "value"]
## 13 12 11 10 9 8 7 6 5 4 3 2 1 13 12 11 10 9 8
## 7 6 5 4 3 2 1 13 12 11 10 9 8 7 6 5 4 3 2
## 1 13 12 11 10 9 8 7 6 5 4 3 2 1
6.2 Deal a Card
จากหัวข้อเป็นการสมมติว่าเราจะแจกไพ่ โดยจะเป็นการนำ R Notation มาสร้างเป็นฟังก์ชัน เพื่อคืนค่าเป็น row ในลักษณะของ Data Frame โดยการสร้างฟังก์ชันจะใช้ Keyword ว่า function ในการสร้าง
deal <-function(cards) {
# ?
}
หรือ
deal <-function(cards) {
cards[1, ]
}
ใน Object cards จะเป็นชุดข้อมูลไพ่ที่บอกให้ส่งค่าออกมา 1 แถว ทุกคอลัมน์ ถ้าลองเรียกฟังก์ชันนี้จะพบว่า มันคืนค่าออกมาเป็นแถวที่ 1 เสมอ
deal(deck)
## face suit value
## king spades 13
deal(deck)
## face suit value
## king spades 13
deal(deck)
## face suit value
## king spades 13
6.3 Shuffle the Deck
จากปัญหาในหัวข้อที่แล้วเราจะมาแก้โดยใช้เทคนิคการ Shuffle หรือ สลับไพ่โดยการสุ่มค่าไม่ให้ซ้ำเดิม ถ้าลองดูข้อมูล 5 บรรทัดแรก จะเห็นว่า deck หรือสำรับไพ่ เรียงตั้งแต่ 1 ถึง 52
deck2 <- deck[1:52, ]
head(deck2)
## face suit value
## king spades 13
## queen spades 12
## jack spades 11
## ten spades 10
## nine spades 9
## eight spades 8
ทำการสุ่มค่าด้วยฟังก์ชัน sample
random <-sample(1:52, size = 52)
random
## 35 28 39 9 18 29 26 45 47 48 23 22 21 16 32 38 1 15 20
## 11 2 4 14 49 34 25 8 6 10 41 46 17 33 5 7 44 3 27
## 50 12 51 40 52 24 19 13 42 37 43 36 31 30
deck4 <- deck[random, ]
head(deck4)
## face suit value
## five diamonds 5
## queen diamonds 12
## ace diamonds 1
## five spades 5
## nine clubs 9
## jack diamonds 11
แล้วลองประยุกต์มาสร้างฟังก์ชัน shuffle โดยเขียน code ดังนี้
shuffle <-function(cards) {
random <-sample(1:52, size = 52)
cards[random, ]
}
โดยปกติ ให้ลองนึกถึงการแจกไพ่จริงๆ จะมีการแจกไพ่ที่ไม่ซ้ำกัน ดังนั้นจะต้องนำค่าที่สุ่มได้นำมาเก็บลงใน object สักตัวหนึ่งก่อน
deal(deck)
## face suit value
## king spades 13
deck2 <-shuffle(deck)
deal(deck2)
## face suit value
## jack clubs 11
6.4 Dollar Signs and Double Brackets
เราสามารถที่จะ extract ค่าจากข้อมูลใน data frame ได้โดยใช้ Dollar Signs $ ยกตัวอย่าง เช่น ต้องการดึงค่าออกมาจาก สำรับไพ่ หรือ deck โดยไม่ต้องแสดงตัวแปร เราจะใช้ notation ชื่อ value
deck$value
## 13 12 11 10 9 8 7 6 5 4 3 2 1 13 12 11 10 9 8 7
## 6 5 4 3 2 1 13 12 11 10 9 8 7 6 5 4 3 2 1 13
## 12 11 10 9 8 7 6 5 4 3 2 1
ค่าที่ได้เป็น Vector ที่มีแต่ตัวเลขเราสามารถนำมาประยุกต์ใช้ อย่างเช่น การหาค่าเฉลี่ย และ ค่ากลาง ทางสถิติ
mean(deck$value)
## 7
median(deck$value)
## 7
นอกจากนี้ เราสามารถที่จะดึงข้อมูลจาก List ได้ สมมติว่าเรากำหนดค่า list ตาม code ด้านล่าง
lst <-list(numbers =c(1, 2), logical = TRUE, strings =c("a", "b", "c"))
lst
## $numbers
## [1] 1 2
## $logical
## [1] TRUE
## $strings
## [1] "a" "b" "c"
เมื่อเราใช้ Dollar sign เราจะได้
lst$numbers
## 1 2
เราสามารถใช้ [[]] hard bucket ที่จะดึงข้อมูลออกมาได้เลยโดยไม่ต้องใช้ Dollar Sign เช่น
lst["numbers"]
## $numbers
## [1] 1 2
lst[["numbers"]]
## 1 2
6.5 Summary
มาถึงข้อสรุปนี้ เราสามารถที่จะเข้าถึงข้อมูลต่างใน Object ที่มี Data Type ประเภทต่างๆ ได้และยังสามารถนำค่ามาจัดการได้ด้วย
คอร์สนี้ดีมากกกก (ไก่ ล้านตัว) ใครอ่านจบ แนะนำว่าให้ไปสมัครเรียน ติดตามได้ที่ link ด้านล่างนี้เลย
Course Online DATA ROCKIE Bootcamp