สิ่งสำคัญของการสร้าง model ML คือการปรับข้อมูลให้ Normalization และ Scaling
1️⃣ / 8️⃣ จากโพสที่แล้ว เมื่อเราทำการ cleansing data จนได้ระดับที่น่าพอใจแล้ว สิ่งถัดไปที่จะต้องพิจารณาเพิ่มเติม จะขอเขียนในโพสนี้อยู่ 2 เรื่อง คือ
- การกระจายตัวของข้อมูล (Data Distribution)
- สเกลของข้อมูล และ การปรับเปลี่ยนข้อมูลให้มีสเกลเดียวกัน
ซึ่งทั้งสองเรื่องนี้ เป็นสิ่งสำคัญที่จะต้องทำก่อนที่จะนำข้อมูลไปสร้างเป็น Model Machine learning
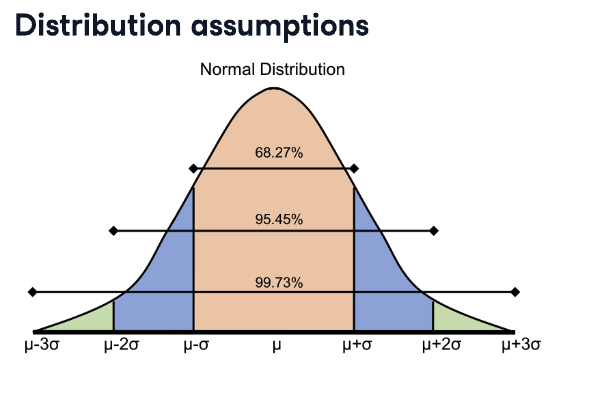
2️⃣ / 8️⃣ การกระจายตัวของข้อมูล (Data Distribution)
สิ่งที่สำคัญจะเข้าใจก่อนที่จะสร้าง Model Machine Learning คือ จะต้องรู้ว่าข้อมูลมีการกระจายตัวอย่างไร เพราะใน Model Machine Learning หลายๆ Algorithm นั้น ถึงแม้ว่าจะมีคุณลักษณะที่แตกต่างกัน แต่ว่า ทุกๆ Model ต้องการการกระจายตัวของข้อมูลอยู่ในรูปแบบของ Normal Distribution (กระจายตัวแบบปกติ)
3️⃣ / 8️⃣ หลังจากที่ กรองข้อมูลทำ cleansing data ทั้งหมดแล้ว ก็จะต้องมาพิจารณาในเรื่องของกระจายตัวต่อ สามารถที่จะใช้เครื่องมือ หรือ กราฟเพื่อแสดงผล ได้อย่าง Boxplot หรือ Histrogram เพื่อดูการกระจายตัวก่อนนำไปใช้งาน
4️⃣ / 8️⃣ สเกลของข้อมูล และ การปรับเปลี่ยนข้อมูลให้มีสเกลเดียวกัน
นอกจากการกระจายตัวของข้อมูลจะมีผลต่อประสิทธิภาพของ Model Machine Learning แล้วนั้น สิ่งที่สำคัญอีกเรื่องหนึ่ง คือ สเกลของข้อมูล
ชุดข้อมูลต่างๆ นั้น ล้วนมีความแตกต่างของชนิดของข้อมูล บ้างอาจจะเป็นชนิดข้อมูลแบบ category หมวดหมู่ ที่เป็นเลขจำนวนเต็มเพียงหลักเดียว หรือ เป็นข้อมูลรายได้ที่มีเลขหลายหลัก เช่น 30000 เป็นต้น เมื่อทั้ง 2 ชนิดนำไปเข้า model machine learning จะไม่มีประสิทธิภาพ เพราะว่า ค่าความแปรปรวน หรือ การกระจายตัวนั้นสูง ผลลัพท์ในการทำนายก็จะผิดพลาดสูงตามไปด้วย
5️⃣ / 8️⃣ เทคนิคการปรับข้อมูลให้อยู่ใน scale เดียวกันมีอยู่หลายวิธี แต่วิธีที่นิยมใช้กัน มีอยู่ 2 วิธีคือ
- Normalization (Min-Max Scaling)
- Standardization (Z-score Scaling)
- Log Transform
6️⃣ / 8️⃣ Normalization (Min-Max Scaling)
Min-Max Scaling มักนำมาใช้เมื่อคุณต้องการให้ข้อมูลอยู่ในช่วงที่กำหนดไว้ โดยทั่วไปแล้วระหว่าง 0 ถึง 1 ซึ่งเป็นที่นิยมในการใช้ในการฝึกฝนข้อมูลในการเรียนรู้ของเครื่อง เช่นการใช้ Neural Networks และ K-Means Clustering
7️⃣ / 8️⃣ Standardization (Z-score Scaling)
Standardization มักนำมาใช้เมื่อคุณต้องการปรับข้อมูลให้อยู่ในรูปแบบที่มีความสามารถในการทำนายที่ดีขึ้นเมื่อมีการใช้สเกลเลอร์แบบ Z-score โดยเฉพาะในอัลกอริทึมที่ใช้การคำนวณระยะห่าง เช่น K-Nearest Neighbors (KNN) และ Principal Component Analysis (PCA)
8️⃣ / 8️⃣ Log Transform
log transform นั้นจะใช้เมื่อข้อมูลมีขนาดใหญ่มากๆ จะปรับลดขนาดลงมาเพื่อให้ใกล้เคียงกับค่าอื่นๆในชุดข้อมูล
กด ads เป็นกำลังใจให้ผู้เขียน และสามารถติดตามได้ที่ fb paeg